常用命令
grep
通常用法
|
|
OR逻辑
|
|
与逻辑
|
|
正则
grep中的正则表达式分为3种:
- basic (BRE)
- extended (ERE),通过
-E参数开启 - perl (PCRE),通过
-P参数开启
ERE模式
|
|
PCRE模式
|
|
Regular expressions in grep ( regex ) with examples
source
使用方式: source file
说明: 在当前环境下读取并执行file中的命令
|
|
日期时间
|
|
文件查找
|
|
screen
|
|
awk
|
|
其他
|
|
Shell
变量
|
|
数组
|
|
条件判断
|
|
命令执行
|
|
文件系统
属性
|
|
改变文件权限及属性
|
|
用户和用户组
|
|
进程管理
什么是进程
进程是操作系统上非常重要的概念,所有系统上面跑的数据都会以进程的类型存在。在 Linux 系统当中:触发任何一个事件时,系统都会将它定义成为一个进程,并且给予这个进程一个 ID,称为 PID,同时根据触发这个进程的用户,给予这个 PID 一组有效的权限设置。
父进程&子进程
当我们登录系统后,会取得一个 bash shell,然后我们利用这个 bash 提供的接口去执行另一个命令,例如 bash 或者 ps 等。那些另外执行的命令也会被触发成为 PID,那个后来执行的命令产生的 PID 就是“子进程”,而原本的 bash 环境下,就称为“父进程”了。
老进程成为新进程的父进程(parent process),而相应的,新进程就是老的进程的子进程(child process)。一个进程除了有一个PID之外,还会有一个PPID(parent PID)来存储的父进程 PID。如果我们循着 PPID 不断向上追溯的话,总会发现其源头是 init 进程。所以说,所有的进程也构成一个以 init 为根的树状结构。
fork & exec
当计算机开机的时候,内核(kernel)只建立了一个 init 进程。Linux kernel 并不提供直接建立新进程的系统调用。剩下的所有进程都是 init 进程通过 fork 机制建立的。新的进程要通过老的进程复制自身得到,这就是 fork。fork 是一个系统调用。进程存活于内存中。每个进程都在内存中分配有属于自己的一片空间 (内存空间,包含栈、堆、全局静态区、文本常量区、程序代码区)。当一个程序调用 fork 的时候,实际上就是将上面的内存空间,又复制出来一个,构成一个新的进程,并在内核中为该进程创建新的附加信息 (比如新的 PID,而 PPID 为原进程的 PID)。此后,两个进程分别地继续运行下去。新的进程和原有进程有相同的运行状态(相同的变量值,相同的指令…)。我们只能通过进程的附加信息来区分两者。
程序调用 exec 的时候,进程清空自身的内存空间,并根据新的程序文件重建程序代码、文本常量、全局静态、堆和栈(此时堆和栈大小都为 0),并开始运行。
孤儿进程和僵尸进程
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵尸进程。
进程状态

Linux中进程分三种状态(对应三状态模型中的三种必备状态):
- 阻塞进程(blocked process)
- 可运行进程(runnable process)
- 正在运行的进程(running process)
阻塞状态是指线程因为某种原因放弃了CPU执行权,暂停运行,此时不会获取到cpu时间片,直到线程进入可运行状态(runnable),才有机会再次获得cpu执行权转到运行状态。
睡眠、挂起是行为,阻塞是状态。睡眠后进程进入阻塞状态,定时器过期后会自动回复就绪状态;挂起操作后需要主动恢复挂起。
进程的状态转换
进程的三态模型
按进程在执行过程中的不同情况至少要定义三种状态:
运行(running)态:进程占有处理器正在运行的状态。
进程已获得CPU,其程序正在执行。在单处理机系统中,只有一个进程处于执行状态; 在多处理机系统中,则有多个进程处于执行状态。
就绪(ready)态:进程具备运行条件,等待系统分配处理器以便运行的状态。
当进程已分配到除CPU以外的所有必要资源后,只要再获得CPU,便可立即执行,进程这时的状态称为就绪状态。在一个系统中处于就绪状态的进程可能有多个,通常将它们排成一个队列,称为就绪队列。
等待(wait)态:又称阻塞态或睡眠态,指进程不具备运行条件,正在等待某个时间完成的状态。
也称为等待或睡眠状态,一个进程正在等待某一事件发生(例如请求I/O而等待I/O完成等)而暂时停止运行,这时即使把处理机分配给进程也无法运行,故称该进程处于阻塞状态。

引起进程状态转换的具体原因如下:
运行态→等待态:等待使用资源;如等待外设传输;等待人工干预。
等待态→就绪态:资源得到满足;如外设传输结束;人工干预完成。
运行态→就绪态:运行时间片到;出现有更高优先权进程。
就绪态—→运行态:CPU 空闲时选择一个就绪进程。
进程的五态模型
五态模型在三态模型的基础上增加了新建态(new)和终止态(exit)。
新建态:对应于进程被创建时的状态,尚未进入就绪队列。
创建一个进程需要通过两个步骤:
1.为新进程分配所需要资源和建立必要的管理信息。
2.设置该进程为就绪态,并等待被调度执行。
终止态:指进程完成任务到达正常结束点,或出现无法克服的错误而异常终止,或被操作系统及有终止权的进程所终止时所处的状态。
处于终止态的进程不再被调度执行,下一步将被系统撤销,最终从系统中消失。
终止一个进程需要两个步骤:
1.先等待操作系统或相关的进程进行善后处理(如抽取信息)。
2.然后回收占用的资源并被系统删除。

引起进程状态转换的具体原因如下:
NULL→新建态:执行一个程序,创建一个子进程。
新建态→就绪态:当操作系统完成了进程创建的必要操作,并且当前系统的性能和虚拟内存的容量均允许。
运行态→终止态:当一个进程到达了自然结束点,或是出现了无法克服的错误,或是被操作系统所终结,或是被其他有终止权的进程所终结。
运行态→就绪态:运行时间片到;出现有更高优先权进程。
运行态→等待态:等待使用资源;如等待外设传输;等待人工干预。
就绪态→终止态:未在状态转换图中显示,但某些操作系统允许父进程终结子进程。
等待态→终止态:未在状态转换图中显示,但某些操作系统允许父进程终结子进程。
终止态→NULL:完成善后操作。
进程的七态模型
三态模型和五态模型都是假设所有进程都在内存中的,事实上有序不断的创建进程,当系统资源尤其是内存资源已经不能满足进程运行的要求时,必须把某些进程挂起(suspend),对换到磁盘对换区中,释放它占有的某些资源,暂时不参与低级调度。起到平滑系统操作负荷的目的。
引起进程挂起的原因是多样的,主要有:
1.终端用户的请求。当终端用户在自己的程序运行期间发现有可疑问题时,希望暂停使自己的程序静止下来。亦即,使正在执行的进程暂停执行;若此时用户进程正处于就绪状态而未执行,则该进程暂不接受调度,以便用户研究其执行情况或对程序进行修改。我们把这种静止状态成为“挂起状态”。
2.父进程的请求。有时父进程希望挂起自己的某个子进程,以便考察和修改子进程,或者协调各子进程间的活动。
3.负荷调节的需要。当实时系统中的工作负荷较重,已可能影响到对实时任务的控制时,可由系统把一些不重要的进程挂起,以保证系统能正常运行。
4.操作系统的需要。操作系统有时希望挂起某些进程,以便检查运行中的资源使用情况或进行记账。
5.对换的需要。为了缓和内存紧张的情况,将内存中处于阻塞状态的进程换至外存上。
七态模型在五态模型的基础上增加了挂起就绪态(ready suspend)和挂起等待态(blocked suspend)。
- 挂起就绪态:进程具备运行条件,但目前在外存中,只有它被对换到内存才能被调度执行。
- 挂起等待态:表明进程正在等待某一个事件发生且在外存中。

引起进程状态转换的具体原因如下:
等待态→挂起等待态:操作系统根据当前资源状况和性能要求,可以决定把等待态进程对换出去成为挂起等待态。
挂起等待态→挂起就绪态:引起进程等待的事件发生之后,相应的挂起等待态进程将转换为挂起就绪态
挂起就绪态→就绪态:当内存中没有就绪态进程,或者挂起就绪态进程具有比就绪态进程更高的优先级,系统将把挂起就绪态进程转换成就绪态。
就绪态→挂起就绪态:操作系统根据当前资源状况和性能要求,也可以决定把就绪态进程对换出去成为挂起就绪态。
挂起等待态→等待态:当一个进程等待一个事件时,原则上不需要把它调入内存。但是在下面一种情况下,这一状态变化是可能的。当一个进程退出后,主存已经有了一大块自由空间,而某个挂起等待态进程具有较高的优先级并且操作系统已经得知导致它阻塞的事件即将结束,此时便发生了这一状态变化。
运行态→挂起就绪态:当一个具有较高优先级的挂起等待态进程的等待事件结束后,它需要抢占 CPU,而此时主存空间不够,从而可能导致正在运行的进程转化为挂起就绪态。另外处于运行态的进程也可以自己挂起自己。
新建态→挂起就绪态:考虑到系统当前资源状况和性能要求,可以决定新建的进程将被对换出去成为挂起就绪态。
挂起进程等同于不在内存中的进程,因此挂起进程将不参与低级调度直到它们被调换进内存。
挂起进程具有如下特征:
- 该进程不能立即被执行
- 挂起进程可能会等待一个事件,但所等待的事件是独立于挂起条件的,事件结束并不能导致进程具备执行条件。 (等待事件结束后进程变为挂起就绪态)
- 进程进入挂起状态是由于操作系统、父进程或进程本身阻止它的运行。
- 结束进程挂起状态的命令只能通过操作系统或父进程发出。
用户CPU时间=程序运行状态用户空间的时间
系统CPU时间=程序运行状态下内核空间的时间
程序运行时间=用户CPU时间+系统CPU时间
进程调度
默认时间片轮转法
信号
|
|
SIGINT/SIGTERM/SIGKILL的区别
三者都用于结束进程运行。
SIGINT与字符ctrl+c绑定,且只能结束前台进程
SIGTERM优雅结束信号。该信号可以被阻塞、处理或忽略,使得进程可以友好退出。
SIGKILL强制结束,该信号不可忽略
USR1 和 USR2 用户自定义信号
信号捕获处理
shell 下捕获信号
|
|
相关命令
|
|
相关概念
CPU相关
如何理解平均负载
CPU上下文切换
上节我们了解到多个进程竞争CPU会造成系统负载升高,这里你一定有疑惑,进程在竞争CPU的时候并没有真正运行,为什么还会造成系统负载升高呢?
Linux是一个多任务操作系统,它支持远大于cpu数量的任务同时运行。当然,这些任务实际上并不是真正的同时运行,而是因为系统在很短的时间内,将CPU轮流分配给它们,造成多任务同时运行的错觉。
而每个任务运行前,CPU都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好CPU寄存器和程序计数器(Program Counter,PC)
CPU寄存器,是CPU内置的容量小但速度极快的内存。而程序计数器(PC),则是用来存储CPU正在执行的指令位置、或即将执行的下一条指令位置。它们都是CPU在运行任何任务前,必须的依赖环境,因此也被叫做CPU上下文

知道了什么是CPU上下文,自然也就理解了什么是CPU上下文切换。CPU上下文切换就是把前一个任务的CPU上下文保存起来,然后加载新任务的上下文到寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加再进来。这样就能保证原来的状态不受影响,让任务看起来还是连续运行。
有人会说,CPU上下文切换无非就是更新了CPU寄存器的值嘛,但这些寄存器本身就是为了快速运行任务而设计的,为什么会影响系统的CPU性能呢?
这时我们想一下操作系统管理的”任务”到底是什么?任务包括进程、线程及硬件通过触发信号中断处理程序这三种
于是根据任务不同,CPU上下文分为几种不同的情况,也就是进程上下文切换、线程上下文切换以及中断上下文切换
进程上下文切换
Linux按特权等级,把进程的运行空间分为内核空间和用户空间
- 内核空间(ring 0)具有最高权限,可以直接访问所有资源
- 用户空间(ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入内核中才能访问到这些特权资源

换个角度,也就是说,进程既可以在用户空间运行,又可以在内核空间运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态
从用户态到内核态转变,需要通过系统调用来完成。在系统调用过程中发生了CPU上下文的切换
CPU寄存器里原来用户态的指令位置,需要先保存起来。接着为了执行内核态代码,CPU寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务
而系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行程序。所以,一次系统调用的过程,其实是发生了两次CPU上下文切换
不过,需要注意,系统调用过程中,并不涉及到虚拟内存等进程用户态的资源,也不会切换进程,这点和通常所说的进程上下文切换是不同的:
- 进程上下文切换,是指从一个进程调换到另一个进程运行
- 而系统调用过程中一直是同一个进程在运行
所以,系统调用过程通常称为特权模式切换,而不是上下文切换

说完了系统调用,进程上下文切换和系统调用又有什么关系呢?
首先,你要知道进程是由内核来管理和调度、进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步: 在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载到下一进程的内核态后,还需要刷新新进程的虚拟内存和用户栈
保存上下文和恢复上下文的过程并不是“免费”的,需要内核在CPU上运行才能完成
根据Tsuna的测试报告,每次上下文切换都需要几十纳秒到数微妙的cpu时间。在进程上下文切换次数较多时,很容易导致CPU将大量的时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这是导致平均负载升高的一个重要因素。
另外,linux通过TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB也需要刷新,内存的访问也会随之变慢。特别是多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程
知道了进程上下文切换潜在的性能问题后,我们再来看什么时候切换进程上下文?
显然,进程切换时才会需要切换上下文,那么进程什么时候才会被调度到CPU上运行呢?
- 很容易想到的一个时机,就是进程执行完终止了,它之前使用的CPU就会释放出来,这个时候再从就绪队列里,拿一个新的进程过来执行
- 进程的时间片耗尽,被系统挂起,切换到其他正在等待CPU的进程运行
- 进程系统资源不足(比如内存不足)时,需要等到资源满足后才可以运行,这时进程被挂起,系统调度其他进程运行
- 当进程通过sleep这样的方法主动挂起
- 有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行
- 最后,发生硬件中断时,CPU上的进程会被中断挂起,转而执行内核中的中断服务程序
线程上下文切换
线程与进程最大的区别在于,线程是调度的最小单位,而进程则是资源拥有的基本单位。说白了,内核中的任务调度,实际调度对象是线程,而进程只是给线程提供了虚拟内存、全局变量等资源。
- 当进程只有一个线程时,可以认为进程就是线程
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存
这么一来线程的上下文切换可以分为两种情况
- 第一种,前后两个线程属于不同进程。此时因为资源不共享,所以切换过程就跟进程上下文切换一样
- 第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据
这时你应该发现了,虽同为上下文切换,但同进程内的线程切换,要比多进程间的切换消耗更少的资源,这也正是多线程代替多进程的一个优势
中断上下文切换
除了前面两种上下文切换,还有一种场景会切换CPU上下文,那就是中断
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处于用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必须的状态,包括CPU寄存器、内核堆栈、硬件中断参数等。
对同一个CPU来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样的,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外跟进程 上下文切换一样,中断上下文切换需要耗费CPU,切换次数过多也会消耗大量的CPU,甚至降低系统的整体性能。所以当你发现中断次数过多时,就需要注意去排查它是否给你的系统带来严重的性能问题。
大部分情况下,我们认为内核态是CPU的一种特权态,这个特权态下,CPU可以执行特权态才允许执行的指令,访问特权态才允许访问的资源。
简单来说,内核态与用户态是操作系统的两种运行级别,和当前进程无关。
OS通过控制不同的特权态来控制资源分配。一般有两种方法切换特权态,一种是特殊的指令,比如X86的软中断指令,或者大部分RISC系统的系统调用指令,第二种是执行异常或者外部中断。发生切换后,现在到底是哪个进程,其实是无所谓的。
再说说线程与进程。
线程本质就是堆栈,当一段程序在执行,能代表它的是它的过去和现在。”过去”在堆栈中,”现在”则是CPU的所有寄存器,如果我们要挂起一个线程,我们把寄存器也保存到堆栈中,我们就具有了它的所有状态,可以随时恢复它。这是线程。
当我们切换线程的时候,同时切换它的地址空间(通过修改MMU即可),则我们认为发生了进程切换,所以进程的本质是地址空间,我们可以认为地址空间决定了进程是否发生切换。
用户态切换到内核态的3种方式
- 系统调用
- 系统调用的本质也是中断(软中断)
- 异常
- 运行在用户态下的程序发生了某些实现不可知的异常,这时会触发由当前运行进程到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
- 外围设备中断
这三种是系统运行时由用户态转到内核态的三种方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。
用户栈与内核栈
内核在创建进程的时候,在创建task_struct的同时,会为进程创建相应的堆栈。每个进程都有两个栈,一个用户栈,存在于用户空间;一个内核栈,存在于内核空间。当进程在用户空间运行时,CPU堆栈指针寄存器里面的内容都是用户栈地址,使用用户栈;当进程在内核空间时,CPU堆栈指针寄存器里的内容是内核栈空间地址,是用内核栈
当进程因为中断或者系统调用陷入到内核态时,进程所使用的堆栈也要从用户栈转到内核栈。进程陷入到内核态后,先把用户态堆栈的地址保存在内核栈中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态之后时,在内核态之后的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了用户栈和内核栈的互转。
那么,知道内核转到用户态时,用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,如何知道内核栈的地址?关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,内核保存进程在内核态运行的相关信息,但是一旦进程返回到用户态,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核时得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
性能观测
|
|
小结
你应该知道
- CPU上下文切换,是保证Linux系统正常工作的核心功能之一,一般情况下不需要我们特别关注
- 但过多的上下文切换,会把CPU时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。
Linux软中断
CPU性能优化套路
内存管理
内存映射
通常我们说的内存指的是物理内存,只有内核可以直接访问物理内存。那么进程该如何访问内存呢?
Linux内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址是连续的。通过虚拟地址空间,进程就可以很方便地访问内存。
虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同字长的处理器,地址空间范围也不同,比如常见的32位和64位系统。
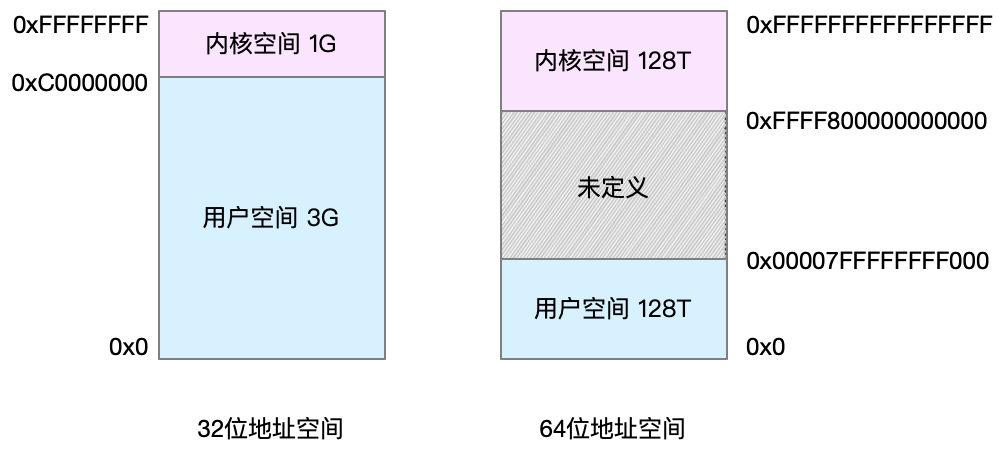
还记得进程的用户态和内核态吗?进程在用户态时只能访问用户空间内存;只有在进入内核态后,才可以访问内核空间内存。
内核空间被所有进程共享,用户空间属于进程私有
内核空间与用户空间一般通过系统调用通信
每个进程都有这么大的地址空间,那么所有进程的虚拟内存加起来,自然比物理内存大得多。所以并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才会分配物理内存,并且分配后的物理内存,是通过内存映射来管理的
内存映射,其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,页表记录了虚拟地址与物理地址的映射关系,如下:

页表实际上存储在CPU的内存管理单元MMU中,这样,处理器就可以直接通过硬件找到要访问的内存。
而当进程访问的虚拟地址在页表中查不到时,系统偶会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
TLB(Translation Lookaside Buffer)会影响CPU的内存访问性能,是因为TLB其实就是MMU的页表的高速缓存。
MMU并不是以字节为单位来管理内存的,而是规定了一个内存映射的最小单位,也就是页,通常是4KB大小。这样每一次内存映射,都需要关联4KB或4KB整数倍的内存空间。
页的大小只有4KB,导致的另外一个问题就是,页表会变得非常大。比方说,32系统需要100多W个页表项(4GB/4KB),才可以实现整个地址空间的映射。为了解决页表项过多的问题,Linux提供两种机制,也就是多级页表和大页(hugePage)
多级页表就是把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,那么,多级页表就只保存这些使用中的区块,这样就可以大大减少页表的项数。

再看大页,其实就是比普通页更大的内存块,常见的大小有2MB和1GB。大页通常在使用大量内存的进程上,比如Orable等。
通过这些机制,在页表的映射下,进程就可以通过虚拟地址来访问物理内存。那么具体到一个Linux进程里,这些内存又是如何使用的呢?
虚拟内存空间分布
以32位系统为例,虚拟内存空间其实又被分为了多个不同的段

1.只读段,包括代码和常量
2.数据段,包括全局常量等
3.堆,包括动态分配的内存,从低向上开始向上增长
4.文件映射段,包括动态库、共享内存等,从高低地址向下增长
5.栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是8MB
内存分配
malloc是C标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即brk()和mmap()
对小块内存(小于128K),C标准库使用brk()来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立即归还系统,而是被缓存起来,这样就可以重复使用
而大块内存(大于128K),则直接使用内存映射mmap()来分配,也就是在文件映射段找一块空闲内存分配出去。
两种方式各有优缺点
Brk()方式的缓存,可以减少缺页异常的发生,提高内存访问效率。不过由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
mmap方式分配的内存,会在释放时直接归还系统,所以每次mmap都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是malloc只对大块内存使用mmap的原因
了解这两种调用方式后,我们还需清除一点,那就是发生两种调用后,其实并没有真正的分配内存。这些内存,都只是首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
整体来讲,Linux使用伙伴系统(Buddy system)来管理内存分配,伙伴系统使用页为单位进行内存管理,并且会通过相邻页的合并减少内存碎片化。你可能会想到,如果有大量比页还小的对象,如果他们都分配单独的页,那岂不是太浪费了?Slab分配器应运而生,专门为小内存分配而生。slab分配器分配内存以字节为单位。slab分配器并没有脱离伙伴系统,而是基于伙伴系统分配的大内存进一步分成小内存分配。
所以在用户空间,malloc通过brk()分配的内存,在释放时并不立即归还系统,而是缓存起来重复利用;在内核空间,Linux则通过slab分配器来管理小内存。你可以把slab看成构建在伙伴系统上的一个缓存,主要作用就是分配内核中的小对象。
vmalloc解决对内核非连续内存分配,类似用户空间分配虚拟内存,内存逻辑上是连续的,其实映射到并不一定连续的物理内存上。Linux内核借用这个技术,允许内核程序在内核地址空间中分配虚拟地址,同样利用页表(内核页表)将虚拟地址映射到分散的内存页上,以此解决内核内存使用中的外部分片问题
- 外部分片是指系统虽有足够的内存,但却是分散的碎片,无法满足对大块“连续内存”的需求
内存回收
对内存来说,如果只分配不释放,就会造成内存泄漏,甚至会耗尽系统内存。所以,在应用程序用完之后,还需要调用free或unmap(),来释放这些不用的内存。
当然,系统也不会任由某进程用完所有内存,在发现内存紧张时,系统会通过一系列机制来回收内存,比如:
- 回收缓存和缓冲区,比如LRU算法,回收最近使用最少的内存页
- 回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘
- 杀死进程,内存紧张时系统会通过OOM(out of memory),直接杀掉用占用大量内存的进程
第二种方式会用到
交换分区(swap).swap其实是把一块磁盘空间当成内存使用。把进程暂时不用的数据存储到磁盘(换出)。当进程访问这些数据时,再从磁盘读取数据到内存中(换入)。
第三种方式OOM,其实是内核的一种保护机制,它监控进程内存使用情况,并使用oom_score为每个进程内存使用情况评分,oom_score越大越容易被OOM杀死。
- 一个进程消耗的内存越大,oom_score越大
- 一个进程运行占用的cpu越多,oom_score越小
如何查看内存使用情况
|
|
- total是总内存大小(MemTotal and SwapTotal in /proc/meminfo)
- used是已使用内存大小,包含共享内存(calculated as total - free - buffers - cache)
- free是未使用内存大小(MemFree and SwapFree in /proc/meminfo)
- shared是tmpfs使用的内存大小(Shmem in /proc/meminfo)
- Buffer是内核缓冲区使用的内存大小(Buffers in /proc/meminfo)
- Cache是页缓存和slab使用的内存大小(Cached and SReclaimable in /proc/meminfo)
- available是新进程可用内存的大小(估算)
注意available不仅包含未使用内存(free),还包括了可回收的缓存(页缓存cache和部分可回收的slab空间),所以一般会比未使用内存更大。
/proc 是 Linux 内核提供的一种特殊文件系统,是用户跟内核交互的接口。比方说,用户可以从 /proc 中查询内核的运行状态和配置选项,查询进程的运行状态、统计数据等,当然,你也可以通过 /proc 来修改内核的配置
/proc/meminfo 中包含了对Cached、Buffer、Slab的具体解释
|
|
|
|
- VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没真正分配物理内存,也会计算在内
- RES是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括Swap和共享内存
- SHR是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等
- %MEM是进程使用物理内存占系统总内存的百分比
共享内存SHR并不一定是共享的,比如说程序的代码段、非共享的动态链接库,也都算在SHR里。
|
|
总结
对普通进程来说,它能看到的其实是内核提供的虚拟内存,这些虚拟内存还需要通过页表、由系统映射为物理内存。
当进程通过malloc申请内存后,内存并不会立即分配,而是在首次访问时,才通过缺页异常陷入内核中分配内存
由于内核的虚拟地址空间比物理内存大很多,Linux还提供了一系列的机制,应对内存不足的问题,比如缓存的回收、交换分区Swap以及OOM等
内存使用过程:
1.进程向系统发出内存申请请求
2.系统会检查进程的虚拟地址空间是否被用完,如果有剩余,给进程分配虚拟地址
3.系统为这块虚拟地址创建相应的memory mapping(可能多个),并将它放进该进程的page table
4.系统返回虚拟地址给进程,进程开始访问该虚拟地址
5.CPU根据虚拟地址在该进程的page table找到相应的memory mapping,但是该mapping没有物理内存关联,于是产生缺页中断
6.操作系统受到缺页中断后,分配真正的物理内存并将它关联到相应的memory mapping
7.中断处理完成后,CPU就可以访问该内存了
Bufer和Cache
Buffer是对磁盘数据的缓存,而Cache是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
从写的角度不仅可以优化磁盘和文件的写入,对应用程序也有好处,应用程序可以在数据真正落盘前,就去返回做其他工作。
从读的角度来说既可以加速频繁访问的数据,也降低了频繁IO对磁盘的压力。
磁盘是一个块设备,可以划分为不同的分区;在分区之上再创建文件系统,挂载到某个目录,之后才可以在这个目录中读写文件
在读写普通文件时,会经过文件系统,由文件系统负责与磁盘交互;而读写磁盘或者分区时,就会跳过文件系统,也就是所谓的“裸I/O”。这两种读写方式所使用的缓存是不同的。

理论上,一个文件读首先到Block Buffer,然后到Page Cache。有了文件系统才有了Page Cache。在老的Linux上的这两个Cache是分开的。这样对于文件数据,会被Cache两次,这种方案虽然简单,但低效。后期Linux把这两个Cache统一了,对于文件,Page Cache指向Block Buffer,对于非文件则是Block Buffer。比如VM虚拟机,会越过file system,直接操作disk,常说的Direct I/O
内存泄漏了,我该如何定位
产生内存泄漏的原因
- 栈。栈内存由系统自动分配和管理。一旦系统程序超出某个变量的作用域,栈内存就会被系统自动回收,所以不会产生内存泄漏的问题
- 文件映射段。包括动态链接库和共享内存,其中共享内存由程序动态分配和管理。如果程序分配后忘了回收,就会导致内存泄漏。
- 堆。堆内存由应用程序自己来分配管理。除非程序退出,这些堆内存并不会被系统自动释放,而是需要应用程序明确调用库函数free来释放。如果应用程序没有正确释放堆内存,就会造成内存泄漏。
- 数据段。包括全局变量和静态变量,这些变量在定义时就已经确定了大小,所以不会发生内存泄漏
- 只读段,包括程序代码和常量,由于是只读的,不会再去分配内存,所以也不会产生内存泄漏。
综上所述,堆内存和内存映射需要程序来动态管理内存,否则会引发内存泄漏。
相应的工具
memleak
|
|
valgrind
为什么系统swap升高了
在内存管理中,前面经过的缓存和缓冲区通常被叫做文件页(File-backed Page),大部分文件页都可以直接回收,以后在需要时,需要从磁盘重新读取就可以。而那些被程序修改过并暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。
除了缓存和缓冲区,通过内存映射获取的文件映射页也是一种常见的文件页,它也可以被释放掉,下次在访问时从文件重新读取。
除了文件页,还有没有其他内存可以回收呢?比如应用程序动态分配的堆内存,也就是我们在内存管理中说到的匿名页(Anonymous Page),是不是也可以回收呢?
它们还有可能被再次访问,不能被直接回收,但是可以把他们暂时存放到磁盘里,释放内存给其他更需要的进程,这正是Linux的Swap机制,当再次需要访问这些内存时,重新从磁盘读入内存。
Linux在什么时候需要回收内存呢?
有新的大块内存分配请求,但是剩余内存不足。这时系统就需要回收一部分内存,进而尽可能满足新内存请求。这个过程通常被称为直接内存回收
除了直接内存回收,还有一个专门的内核线程用来定期回收内存,也就是kswapd0。为了衡量内存使用情况,kswapd0定义了三个内存阈值,分别是页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。剩余内存使用pages_free表示。
kswapd0定期扫描内存使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存回收操作。
很多时候你明明发现了SWAP升高,可是查验后发现系统剩余内存还很多,这是为什么呢?
内核参数 swappiness 的值的大小,决定着linux何时开始使用swap。
- swappiness=0 时表示尽最大可能的使用物理内存以避免换入到swap.
- swappiness=100 时候表示最大限度使用swap分区,并且把内存上的数据及时的换出到swap空间里面.
- 此值linux的基本默认设置为60,不同发行版可能略微不同.
60表示当你的系统内存使用达到(100-60)时,系统就开始出现有交换分区的使用
|
|
总结下,当内存资源紧张时,Linux通过直接内存回收和定期扫描的方式,来释放文件页和匿名页,以便把内存分配给更需要的进程使用。
- 文件页回收比较容易理解,直接清空,或把脏数据写回磁盘后再释放
- 而对匿名页的回收需要通过swap换出到磁盘中,下次访问时,再从磁盘换入到内存中
小结
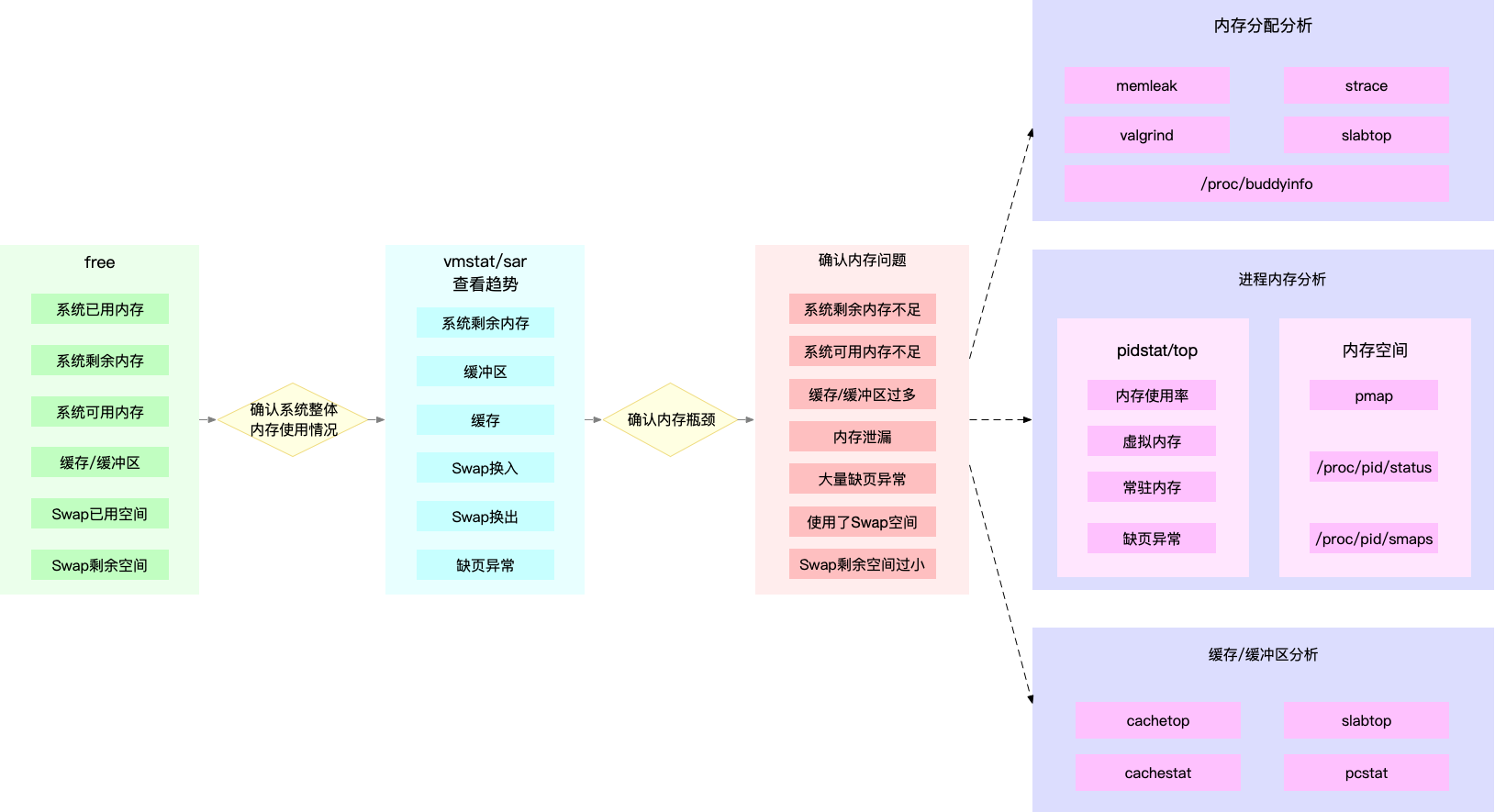

思路: 第一步看系统整体指标(free),接着查看进程内存指标(top/vmstat/pidstat -r)
|
|
文件系统
索引节点和目录项
文件系统,是对存储设备上的文件进行组织管理的机制。组织方式不同,就会形成不同的文件系统。
Linux中一切皆文件,为方便管理Linux文件系统为每个文件分配了两个数据结构
索引节点(index node),用来记录文件的元数据。目录项(directory entry),用来记录文件的名字、索引节点指针及其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
换句话说,索引节点是每个文件的唯一标识,而目录项维护的是文件系统的树状结构。目录项和索引节点的关系是多对一,你可以简单理解为,一个文件可以有多个别名。
举个例子,通过硬链接为文件创建的别名,就会对应不同的目录项,不过这些目录项本质上还是链接同一个文件,所以它们的索引节点相同。
索引节点和目录项记录了文件的元数据及文件间目录关系,那么文件数据到底是怎么存储的呢?是不是直接写到磁盘中就好了呢?
实际上磁盘读写的最小单位是扇区,不过扇区只有512B大小,为提升读写效率,文件系统把连续的扇区组成了逻辑块,然后每次都以逻辑块为最小单元来管理数据。常见的逻辑块大小为4KB,也就是由8个扇区组成。
每个逻辑块内最多放置一个文件的数据,如果文件大于逻辑块大小,则占用多个逻辑块;如果文件小于单个逻辑块大小,该逻辑块剩余的大小不能再被使用(被浪费)。
对于文件系统整体性的信息,存储在磁盘一个名叫超级块的区域中
磁盘在在文件系统格式化时,会被分成三个存储区域
- 超级块,存储文件系统的整体性信息,比如inode与block总量、使用量、剩余量等
- 索引节点区,用来存储索引节点(inode),inode中记录着文件属性,一个文件占用一个inode,同时记录此文件数据所在的逻辑块号码
- 数据块区,用来存储文件数据,如果某个文件太大,会占用多个逻辑块
目录项、索引节点、逻辑块以及超级块构成了文件系统的四大基本要素。
下图展示了超级块、目录项、索引节点及文件数据的关系
虚拟文件系统
为支持不同的文件系统,Linux内核在用户进程和文件系统中间,引入了一个抽象层,也就是虚拟文件系统VFS(Virtual File System)
VFS定义了一组所有文件系统都支持的数据结构和标准接口。
VFS下方支持各种各样的文件系统,按存储位置不同,这些文件系统分为三类
- 基于磁盘的文件系统,例如ext4
- 基于内存的文件系统,这类文件系统,不需要任何磁盘分配存储空间,但会占用内存,例如/proc
- 基于网络的文件系统,NFS等
这些文件系统,要先挂载到VFS目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。
文件系统IO
文件系统挂载到挂载点后,你就能通过挂载点访问文件系统内部的文件了。VFS提供一组标准的文件访问接口。这些接口以系统调用的方式供应用程序使用。
文件读写方式各式各样,通常有以下四种分类:
第一种,根据是否利用标准库缓存,可以把文件IO分为缓冲IO与非缓冲IO
第二种,根据是否利用操作系统的页缓存,可以把文件I/O分为直接I/O与非直接I/O
直接I/O,需要在系统调用时指定O_DIRECT标志,默认是非直接I/O。如果是数据库等场景中,你还会看到跳过文件系统读写磁盘的情况,也就是我们通常说的裸I/O
第三种,根据应用程序是否阻塞自身运行,可以把文件I/O分为阻塞IO和非阻塞IO
第四种,根据是否等待响应结果,分为同步IO和异步IO
你可能发现了,这里好多概念也经常出现在网络编程中。比如非阻塞IO。你也应该理解,”Linux一切皆文件”的深刻含义。无论是普通文件、块文件还是网络套接字和管道,它们都通过统一的VFS接口来访问。
为了降低慢速磁盘对性能的影响,文件系统又通过页缓存、目录项缓存以及索引节点缓存,缓和磁盘延迟对应用程序的影响。
性能观测
|
|
容量
|
|
缓存
free输出的cache大小是页缓存和slab缓存之和,可以通过/proc/meminfo分别获取对应大小
|
|
内核使用Slab机制管理目录项和索引节点缓存。/proc/meminfo只给出了Slab的整体大小,具体到每一种Slab缓存,需要查看/proc/slabinfo文件。
/proc/slabinfo中列比较多,更多时候我们用slabtop来查找占用内存最多的缓存类型。
|
|
文件系统I/O性能指标
- 容量、使用量、剩余空间
除磁盘本身存储情况外,索引节点使用情况也十分重要,它也包括容量、使用量以及剩余量等三个指标。
- 缓存使用情况,包括页缓存、目录项缓存、索引节点缓存以及各个具体文件系统的缓存
磁盘性能 指标
- 使用率
- IOPS
- 吞吐量
- 响应时间
性能工具
|
|

Linux性能优化
如何理解“平均负载”
平均负载指单位时间内系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数
所谓可运行状态的进程,指的是正在运行或等待运行的进程(也就是ps aux中处于R状态的进程)
不可中断状态的进程则是处于内核态关键流程中的进程,并且这些流程是不可打断的,比如常见的是等待硬件设备的I/O响应,也就是我们在ps命令中看到的D状态(Uninterruptible Sleep,也称为Disk Sleep)的进程。
比如一个进程向磁盘读写数据时,为保证数据一致性,在得到磁盘回复之前,它不能被其他进程或中断打断,此时进程就处于不可中断状态。如果此时进程被打断了,就容器出现磁盘数据与进程数据不一致的问题。不可中断状态实际是系统对进程和硬件设备的一种保护机制。
|
|
某个应用CPU使用率达100%,该如何处理
|
|
CPU使用率很高,但为啥却找不到高CPU的应用
有可能是一下原因:
- 进程不断地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的CPU,比如因为段错误、配置错误等,这时,进程在退出后可能又被监控系统自动重启了
- 应用里直接调用其他二进制程序,这些程序通常运行时间比较短,很难通过top这种间隔时间比较长的工具发现
|
|
系统中出现大量不可中断进程和僵尸进程怎么办
|
|
可以看到
- iowait太高了,导致系统的平均负载升高
- 僵尸进程不断增多,说明有程序没有正确清理子进程的资源
|
|
|
|
怎么理解Linux软中断
中断其实是一种异步的时间处理机制,可以提高系统的并发处理能力。
为了解决中断处理程序执行过长和中断丢失的问题,Linux将中断处理过程分成了两个阶段,也就是上半部和下半部
- 上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行。
- 下半部由内核触发,也就是我们常说的软中断,特点是延迟执行。延迟处理上半部未完成的工作,通常以内核线程的方式运行
举个例子,网卡收到数据包后,会通过硬件中断的方式,通知内核有新的数据到了,这时,内核就应该调用中断处理程序来响应它。
对于上半部来说,既然是快速处理,其实就是要把网卡的数据读到内存中,然后更新一下硬件寄存器的状态(表示数据已经读好了),最后在发送一个软中断信号,通知下半部做进一步处理
而下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它交给应用程序。
proc文件系统,它是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。查看软终端和内核线程:
- /proc/softirqs 提供了软中断的运行情况
- /proc/interrupts 提供了硬中断的运行情况
|
|
系统软中断CPU使用率升高,我该怎么办
制造现场
|
|
分析问题
|
|

Linux内存是怎么工作的
网络管理
常用命令
| 旧 | 新 | 描述 |
|---|---|---|
| ifconfig | ip addr | 即ip a,网卡ip、mac等管理 |
| Route | ip route | 路由表管理 |
| ip link | 链路层管理 | |
| ip neigh | ARP表 |
|
|
|
|
C10K和C10000K
C是Client的缩写,C10K就是单机同时处理1W个请求(并发连接1W)的问题
C10K问题的来源
最早由Dan Kegel提出,那时服务器还是32位,运行着Linux2.2,只配置了很少的内存(2G)和千兆网卡
从资源上讲,2G内存和千兆网卡的服务器来说,同时处理10000个请求,只要每个请求处理占用不到200KB(2GB/10000)的内存和100Kbit(1000Mbit/1000)的网络带宽就可以。所以物理资源是足够的,接下来是软件的问题,特别是网络I/O模型的问题。
在C10K之前,Linux网络处理都用同步阻塞的方式,也就是每个请求分配一个进程或线程。在请求数100个时,这种方式没问题,但增加到10000个请求时,10000个进程或线程的调度、上下文切换乃至它们占用的内存,都会成为瓶颈。
既然每个请求分配一个线程的方式不合适,那么为了支持10000个并发请求,这里就有两个问题需要我们解决
第一,怎样在一个线程内处理多个请求,也就是要在一个线程内响应多个网络I/O。
第二,怎么更节省资源地处理客户请求,也就是用更少的线程来服务这些请求。
带着这两个问题,我们展开以下优化
I/O模型优化
异步、非阻塞I/O的解决思路。其实就是网络中常用到的I/O多路复用(I/O Multiplexing)。
再次之前我们先了解两种I/O事件通知方式:水平触发和边缘触发,他们常用在套接字接口的文件描述符中
- 水平触发: 只要文件描述符可以非阻塞地执行I/O,就会触发通知。也就是说,应用程序可以随时检查文件描述符的状态,然后再根据状态,进行I/O操作。
- 边缘触发: 只有在文件描述符的状态发生改变(也就是I/O请求到达时),才发送一次通知。这时,应用程序需要尽可能多地执行I/O,直到无法继续读写,才可以停止。如果I/O没执行完,或者因为某种原因没来得及处理,那么本次通知也就丢失了。
接下来我们看I/O多路复用的方法
第一种,使用非阻塞I/O和水平触发通知,比如select或poll
根据刚才水平触发的原理,select和poll需要从文件描述符列表中,找到那些可以执行I/O,然后进行真正的网络I/O读写。由于I/O是非阻塞的,一个线程中就可以同时监控一批套接字的文件描述符,这样就达到了单线程处理多请求的目的。
这种方式最大优点是对应用程序比较友好,它的API非常简单。
但是应用软件使用select和poll时,需要对这些文件描述符里诶表进行轮训,这样请求数多的时候就比较耗时。
select 使用固定长度的位相量,表示文件描述符的集合,因此会有最大描述符数量的限制。比如32位系统中,默认限制是1024,在select内部,检查套接字状态是用轮训的方法,再加上应用软件使用时的轮训,就编程了一个O(n^2)的关系
而poll改进了select的标识方法,换成了一个没有固定长度的数组,这样就没有了最大描述符数量的限制。但是应用程序在使用poll时,同样需要对文件描述符列表进行轮训,这样处理耗时跟描述符数量就是O(N)的关系
除此之外,应用程序每次调用select和poll时,还需要把文件描述符的集合,从用户空间传入内核空间,由内核修改后,再传入用户空间,这样一来一回的切换,也增加了处理成本
第二种,使用非阻塞I/O和边缘触发通知,比如epoll
epoll很好的解决了select和poll的问题
- epoll使用红黑树,在内核中管理文件描述符的集合,这样就不需要应用程序在每次操作时都传入、传出这个集合。
- epoll使用事件驱动机制,只关注有I/O事件发生的文件描述符,不需要轮训扫描整个集合。
不过要注意,epoll是linux2.6中才新增的功能。由于边缘处罚只在文件描述符可读或可写事件发生时才通知,那么应用程序就需要尽可能多地执行I/O,并要处理更多的异常事件。
第三种,使用异步I/O(ASsynchronous I/O,简称AIO)
异步I/O允许应用程序同时发起很多I/O操作,而不用等待这些操作完成,而在I/O完成后,系统会用事件通知的方式,告诉应用程序。这时应用程序才会查询I/O操作的结果
进程工作模型优化
IO多路复用后,就可以在一个线程或进程中处理多个请求,于是就有了两种不同的工作模型
第一种,主进程子进程,这也是最常用的一种模型,这种方法的一个通用工作模式:
- 主进程执行bind()+listen()后,创建了多个子进程
- 然后,在每个子进程中,都要accpet或epoll_wait,来处理相同的套接字
比如nginx就是这么工作的。主进程用于初始化套接字,并管理子进程的生命周期;而worker进程则负责实际的请求处理。
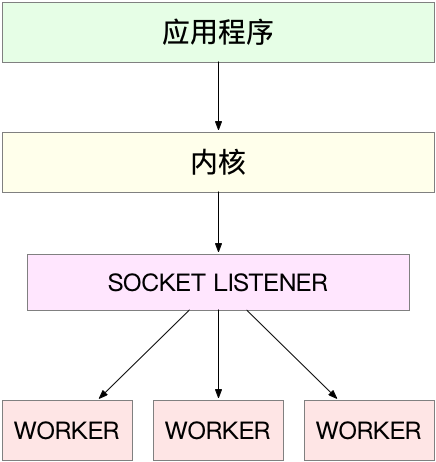
这里要注意,还存在一个惊群的问题。换句话说,多进程(线程)在同时阻塞等待同一个事件,当事件发生时,多个进程(线程)被同时唤醒,但实际上你只有一个进程来响应这个事件(获得事件的”控制权”),其他被唤醒的进程(线程)获取控制权失败都会重新休眠,这种现象就叫惊群效应。惊群效应会造成严重的系统上下文切换代价。
- accept的惊群问题,在LInux2.6中解决了。Linux2.6在内核级别让accept成为原子操作,如果多个进程同时阻塞在accept上,每次仅唤醒等待队列的第一个进程从accecpt返回并拿到用户连接。
- epoll的惊群问题,到了LInux4.5通过EPOLLEXCLUSIVE解决
实际生产环境中,通常是先用select/epoll来监听listen_fd是否有连接过,在调用accept,也就是说惊群点从accept提前到epoll上了。
那么Nginx中是如何解决惊群问题的呢?
nginx在每个worker进程中,都增加了一个全局accept锁(accept_mutex)。这些worker进程需要首先竞争到锁,只有竞争到锁的进程,才会加入到poll中,这样就确保只有一个worker子进程被唤醒。
另外进程的调度管理、上下文切换的成本非常高,为什么使用多进程的模式的nginx却具有非常好的性能呢?
其原因主要是这些worker进程,实际上并不需要经常创建和销毁,而是在没有任务时休眠,有任务时唤醒。
当然你也可以用线程代替进程: 主线程负责套接字初始化和子进程状态的管理,而子进程则负责实际的请求处理。由于线程的调度和切换成本比较低,实际上你也可以进一步把epoll_wait都放到主线程中,保证每次时间都只唤醒主线程,而子线程只需要负责后续的请求处理。
监听到相同端口的多进程模型
在这种方式下,所有进程都监听相同的接口,并且开启SO_REUSEPORT选项,由内核负责将请求负载均衡到这些监听进程中去。这一过程如下:

由于内核确保了只有一个进程被唤醒,就不会出现惊群问题了。比如Nginx在1.9.1就已经支持了这种模式
启用前 一个单独的监听套接字会通知所有的工作进程,每个进程则会试图争抢接管某个连接
启用后
想要使用SO_REUSEPORT选项,需要用Linux3.9以上的版本才可以
C1000K
基于I/O多路复用和请求处理的优化,C10K问题很容易就可以解决。再进一步,C1000K是否也很容易实现?
没那么简单,首先从物理资源上来说,100W个请求需要大量的系统资源,比如
- 假设每个请求需要16KB内存,那么总共偶需要大约15GB内存
- 而从带宽上来讲,假设只有20%活跃连接,即使每个连接只要1KB/s的吞吐量,总共也需要1.6Gb/s的吞吐量(
1000000*0.2*8)。所以需要配置万兆网卡,或者基于多网卡Bonding承载更大的吞吐量
bond通过将多张网卡绑定成一个逻辑网卡,使用同一IP工作,实现了本地网卡的冗余,带宽扩容和负载均衡,在生产环境是一种很常见的技术。
其次,从软件上来说,大量的连接也会占用大量的软件资源,比如文件描述符的数量、连接状态的追踪(CONNTRACK)、网络协议栈的缓存大小(比如套接字读写缓存、TCP读写缓存等)
最后大量请求带来的中断处理,也会带来非常高的处理成本。
C1000K的解决办法,本质上还是构建在epoll的非阻塞I/O模型上。只不过,除了I/O模型外,还需要从应用程序到Linux内核、再到CPU、内存和网络各个层次的深度优化、特别是需要借助软件,来卸载那些原本通过软件处理的大量功能。
C10M
实际上在C1000K问题中,各种软件、硬件优化基本已经做到头了,你可能会发现,无论怎么优化应用程序和内核中的各种网络参数,想实现1000W请求的并发,都是极其困难的。
究其原因,还是Linux内核协议栈做了太多繁重的工作。从网卡中断带来的硬终端处理程序开始,到软终端中的隔层协议网络处理,最后再到应用程序,这个路径是在太长了。
要解决这个问题,最重要的就是跳过内核协议栈的冗长路径,把网络包直接发送到要处理的应用程序那里,这里有两种常见的机制:DPDK和XDP
第一种机制,DPDK,是用用户态网络的标准。它跳过内核协议栈,直接由用户态进程通过轮训的方式来处理网络接收。

说起轮训,你肯定下意识认为它是低效的象征,但是进一步范文自己,它的低效主要体现在哪里?是查询时间明显躲过实际工作时间的情况下吧!那么换个角度想,如果每时每刻都有新的网络包需要处理,轮训的优势就很明显了,比如:
- 在PPS非常高的场景中,查询时间比实际工作时间少了很多,绝大部分时间都在处理网络包
- 而跳过内核协议后,就省去了冗杂的硬终端、软终端再到Linux网络协议栈逐层处理的过程,应用程序可以针对应用的实际场景,有针对性的优化网络包的处理逻辑,而不需要关注所有细节
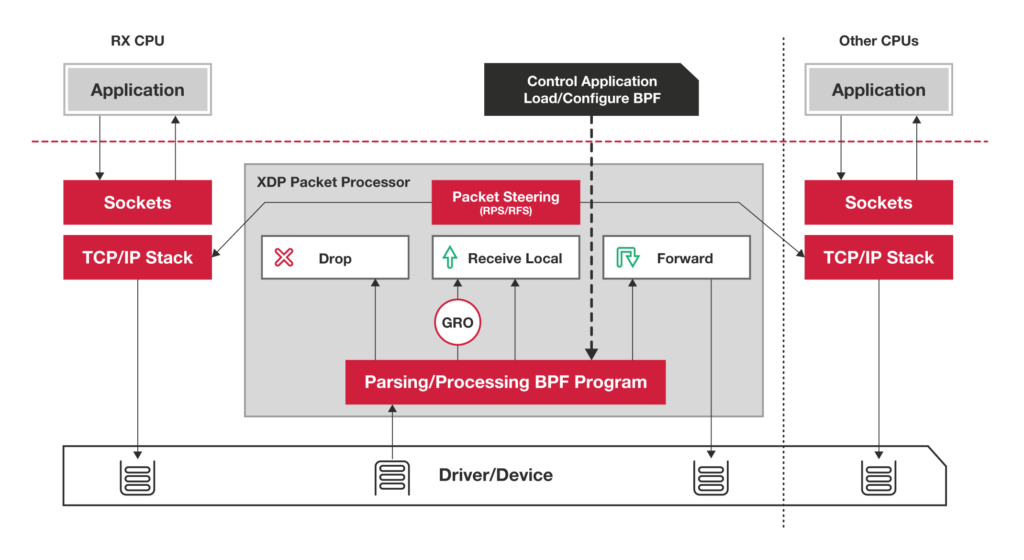
第二种XDP则是Linux内核提供的一种高性能网络处理路径。它允许网络包在进入内核协议栈之前就进行处理,也可以带来更高的性能。
其原理如下
小结
C10K问题的根源,一方面在于系统有限的资源;另一方面,也是更重要的因素,是同步阻塞的I/O模型及轮训的套接字接口,限制了网络事件的处理效率。在Linux2.6引入的epoll,完美解决了C10K的问题
从C10K到C1000K,就不仅仅是增加物理资源就能解决的了。这是要做多方面的优化工作,从硬件的中断处理和网络功能卸载、到网络协议栈的文件描述符数量、连接状态跟踪、缓存队列等内核的优化、再到应用程序的工作模型优化,都是考虑的重点
再进一步,要实现C10M,就不止是增加物理资源或优化内核和应用程序就能解决问题了。这时需要用XDP在内核协议栈之前处理网络包;或用DPKD直接跳过网络协议栈,在用户空间通过轮训的方式直接处理网络包。
FAQ
一台机器不是只有65536个端口吗?每个网络请求都需要消耗一个端口,这样大于65536个请求会不会导致端口不够用呢
如果是只有一个IP地址的客户端,那的确是受限于端口数量。不过如果是服务器端,那可以接受的连接就多多了(组合客户端IP+端口)
Epoll什么时候用ET?什么会后用LT
LT简单,易实现;ET极端情况下性能更好,但维护也麻烦
千万连接一般用于什么场景下呢
通常会用在流量集中的场景,比如网关或流量清洗这种安全系统上
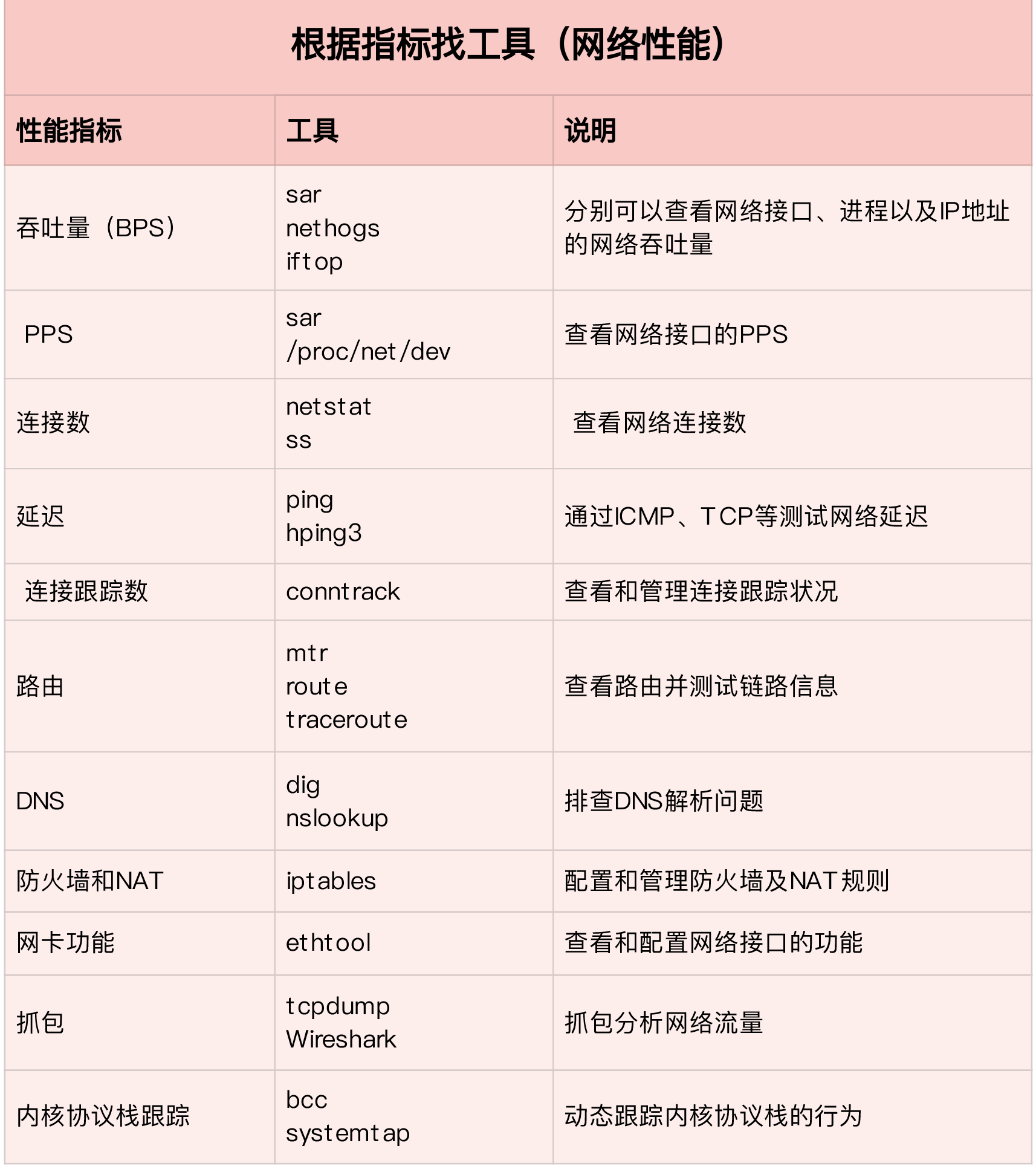
网络性能评估
网络性能指标
- 带宽,表示链路最大传输速率,单位是b/s(比特/秒),常用带宽有1000M,10G,100G等
- 吞吐量,表示没丢包时的最大传输速率,单位通常是b/s或B/s。吞吐量/带宽也就是网络链路使用率
- 延时,从网络请求发出,到收到远端的响应所需要的时间。
- PPS,是Packet per Second的缩写,表示以网络包为单位的传输速率。PPS通常用来评估网络的转发能力。
你可能在很多地方听说过“网络带宽测试”,这里测试的其实是网络吞吐量
PPS通常用在需要大量转发的场景,而对TCP或WEB服务来说,更多会用并发连接数和QPS等指标
网络基准测试
HTTP性能
ab
应用负载性能
wrk
DNS解析时快时慢,如何优化
简单回顾一下之前的内容。Linux网络是基于TCP/IP协议栈构架的,而在协议栈的不同层,我们关注的网络性能指标也不尽相同
在应用层,我们关注的是应用程序的并发连接数、每秒请求数、处理延迟、错误数等,可以用wrk、Jmeter等工具,模拟用户负载,得到想要的测试结果
传输层,我们关注的是TCP、UDP等传输协议的工作状况,比如TCP连接数、TCP重传、TCP错误数等。此外你可以用iperf、netperf等,来测试TCP或UDP的性能
再往下到网络层,我们关注的则是网络包的处理能力,即PPS。linux内核自带的pktgen,就可以帮你测试这个指标
接下来我们一起来了解下DNS。
DNS(Domain Name System),是互联网中最基础的一项服务,主要提供了域名和IP地址之间映射关系的查询服务,也为很多应用提供了动态服务发现和全局负载均衡等机制。
DNS出问题时,该如何排查呢?
域名与域名解析
DNS位于TCP/IP网络栈中的应用层,不过实际传输还是基于UDP或TCP协议(UDP居多),并且域名服务器一般监听在端口53上。
DNS通过资源记录的方式来管理所有数据,它支持A、CNAME、MX、NS等多种类型的记录.比如:
- A记录,用来把域名转换成IP地址
- CNAME用来创建别名
- 而NS记录,则表示该域名对应的域名服务器地址
相关命令
|
|
域名
多级域名
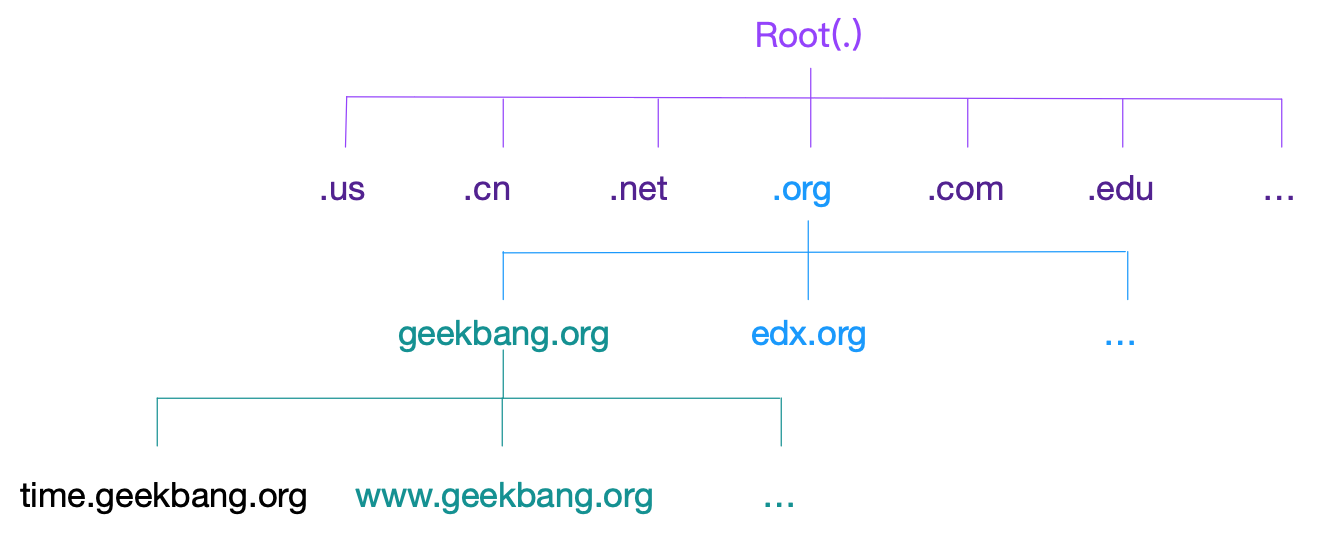
解析下time.geekbang.org,其中.是根域名,org是顶级域名,geekbang是二级域名,time是二级域名
域名解析过程

DNS解析优化
通过dnsmasq等工具对DNS结果做缓存。缓存是最有效的方法,但是要注意,一旦缓存过期,还是要去DNS服务器重新获取新记录。
使用ping值较低的dns服务器
- HTTPDNS。这是很多移动应用会选择的方法,特别是如今域名劫持普遍存在,使用HTTP协议绕过链路中的DNS服务器,就可以避免域名劫持的问题。
Dnsmasq
|
|
如何通过tcpdump和wireshark分析网络流量
怎么缓解DDOS攻击带来的性能下降问题
DDos的前身是Dos(Denial of service) ,即拒绝服务攻击,指利用大量的合理请求,来占用过多的目标资源,从而使目标服务无法响应正常请求。
DDoS(Distributed Denail of Service)则是在Dos基础上,采用了分布式架构,利用多台主机同时攻击目标主机。这样,即使目标服务部署了网络防御设备,面对大量网络请求时,还是无力应对。
根据攻击原理分类
第一种,耗尽带宽
第二种,耗尽操作系统资源,如CPU,内存等
第三种,消耗应用程序的运行资源。
案例分析
假设目前客户端连接服务器出现超时
在服务器端
|
|
可以发现,PPS已经达到20000多,但是BPS只有1174KB,这样每个报的大小就只有54B(1174*1024/22274=54)
这明显是个小包,具体是什么样的小包呢?用tcpdump来看一下
|
|
Flags[S]表示这是一个SYN包,大量SYN报表明,这是一个SYN Flood攻击。如果用wiresharek来观察,则更直观的可以看到SYN Flood的过程

SYN Flood正式互联网中最经典的DDoS攻击方式,从上图可以看到它的原理
- 客户端构造大量的SYN包,请求建立TCP连接
- 而服务器收到包后,向源IP发送SYN+ACK报文,并等待第三次握手的最后一次ACK报文,直到超时
这种等待状态的TCP连接,通常称为半开连接。由于半连接队列的大小有限,大量的半开加链接就会导致半连接队列迅速占满,从而无法建立新的TCP连接。
这其实提醒了我们,查看TCP半开连接的方法,关键在于SYN_RECEIVED状态的连接。
|
|
知道源IP后,要解决SYN攻击只要丢掉相关的包就可以。这时,iptables可以帮你完成这个任务
|
|
但是SYN Flood攻击的源IP并不是固定的。这样刚才的办法就不适用了。
|
|
这样我们初步限制了SYN Flood攻击。不过还不够,因为我们的案例只是单个攻击源。如果是多台机器发送SYN Flood,这种方法就无效了,因为你很可能无法SSH登录到机器上,更别提执行上述所有的排查命令
此外,还需要先对系统做一些TCP优化
半连接的连接数是有限制的,执行下面命令可以看到,默认半连接容量只有256:
|
|
换句话说,SYN包数如果大一些,让半开状态连接超过256,就不能登陆机器了,所以第一步应该增大半连接容量
|
|
另外每个SYN_RECV时,如果失败,内核还会自动重试,并且默认重试次数为5,我们可以调整为1次
|
|
除此之外,刚刚我们看到瓶颈其实一直出在半连接队列上,那么如果没有这个环节,自然问题也就不存在了。TCP SYN Cookies就是这么一种专门防御SYN Flood攻击的方法。
开启SYNC cookies后,就不需要维护半连接状态了,进而也就没有了半连接数的限制
开启TCP synccookies后,内核选项net.ipv4.tcp_max_syn_backlog也就无效了
你可以通过下面命令,开启TCP SYN Cookies:
|
|
注意上面的修改都是临时的,重启后这些配置就会丢失。为了持久化配置,需要写入/etc/sysctl.conf文件中:
|
|
记住,写入/etc/sysctl.conf配置后,需要制定sysctl -p命令后,才会动态生效
DDoS到底该怎么防御
DDoS的分布式、大流量、难追踪等特点,目前还没有办法可以完全防御DDoS带来的为,只能设法缓解影响。
比如购买专业的流量清洗设备和网络防火墙,在网络入口处阻断恶意流量,只保留正常流量进入数据中心的服务器。
在Linux服务器中,可以通过内核调优、DPDK、XDP等多种方法,增大服务器的抗攻击能力,降低DDoS对正常服务的影响。
网络请求延迟变大了,我该怎么办
在服务端抓包,追踪TCP流得到

还不够直观,我们看下流程图,选择Limit to display filter,并设置Flow type 为”TCP Flow”

该图中,左侧是客户端,右边是Nginx服务器。通过这个图,可以看到前面三次握手以及第一次HTTP请求和响应还是挺快的,但是第二次HTTP请求就比较慢了,特别是客户端在收到服务器第一个分组后,40ms后才发出ACK响应(图中蓝色行)
看到40ms这个值,有没有想起什么东西?实际上,这是TCP延迟确认(Delayed ACK)的最小时间。
这里解释一下延迟确认。这是针对TCP ACK的一种优化机制,也就是不用每次请求都发送一个ACK,而是先等一会(比如40ms),看看有没有“顺风车”。如果这段时间内,正好有其他包需要发送,俺么就捎带ACK一起发送过去。当然,如果一直等不到其他包,那就超时后单独发送ACK。
因为案例中40ms发生在客户端上,我们有理由怀疑,客户端开启了延迟确认机制。
查看TCP文档,你会发现,只有TCP套接字专门设置了TCP_QUICKACK,才会开启快速确认模式;否则默认情况下,采用的就是延迟确认机制
|
|
|
|
可以看到wrk只设置了TCP_NODELAY选项,而没有设置TCP_QUICKACK,这说明wrk采用的正是延迟确认,也就解释了40ms的问题。
这是客户端行为,哪里来说,Nginx服务器不应该受到这个行为的影响,我们再看看wireshark

仔细观察,1173号报,也就是刚才说的延迟ACK包;下一行的1175,则是Nginx发送的第二个分组包,它分697号报组合起来,构成了一个完整的HTTP响应(ACK号都是85)
第二个分组没跟前一个分组(697)一起发送,而是等到客户端对第一个分组的ACK后(1173号)才发送,这看起来跟延迟确认有点像,只不过,这不再是ACK,而是发送数据。
这里我们想起了一个东西-Nagle算法(纳格算法)。
Nagle算法是TCP协议中用于减少小包发送数量的一种优化算法,目的是为了提高实际带宽利用率。
Nagle算法通过合并TCP小包,提高网络带宽的利用率。Nagle算法规定,一个TCP连接上,最多只能有一个未被确认的未完成分组;在收到这个分组的ACK前,不发送其他分组。这些小分组会被组合起来,并在收到ACK后,用同一个分组发送出去。
Nagle算法本身想法是挺好的,但是和Linux默认的延迟确认机器一起使用时,网络延迟会明显,如图:

- 当Server发送了第一个分组后,由于Client开启了延迟确认,就需要等待40MS后才会回复ACK
- 同时,由于Server端开启了Nagle,而这时还没收到第一个分组的ACK,Server也会在这里一直等着。
- 直到40ms超时后,Client才会回复ACK,然后,Server才会继续发送第二个分组
那么,如何知道Nginx有没有开启Nagle呢?
查询文档,我们知道只有在设置了TCP_NODELAY后,Nagle算法才会禁用。
|
|
查看Nginx配置
|
|
将tcp_nodelay开启后问题解决。
小结
LInux网络协议栈,在此我们用一张图表示这个结构:

网络协议栈及收发流程:
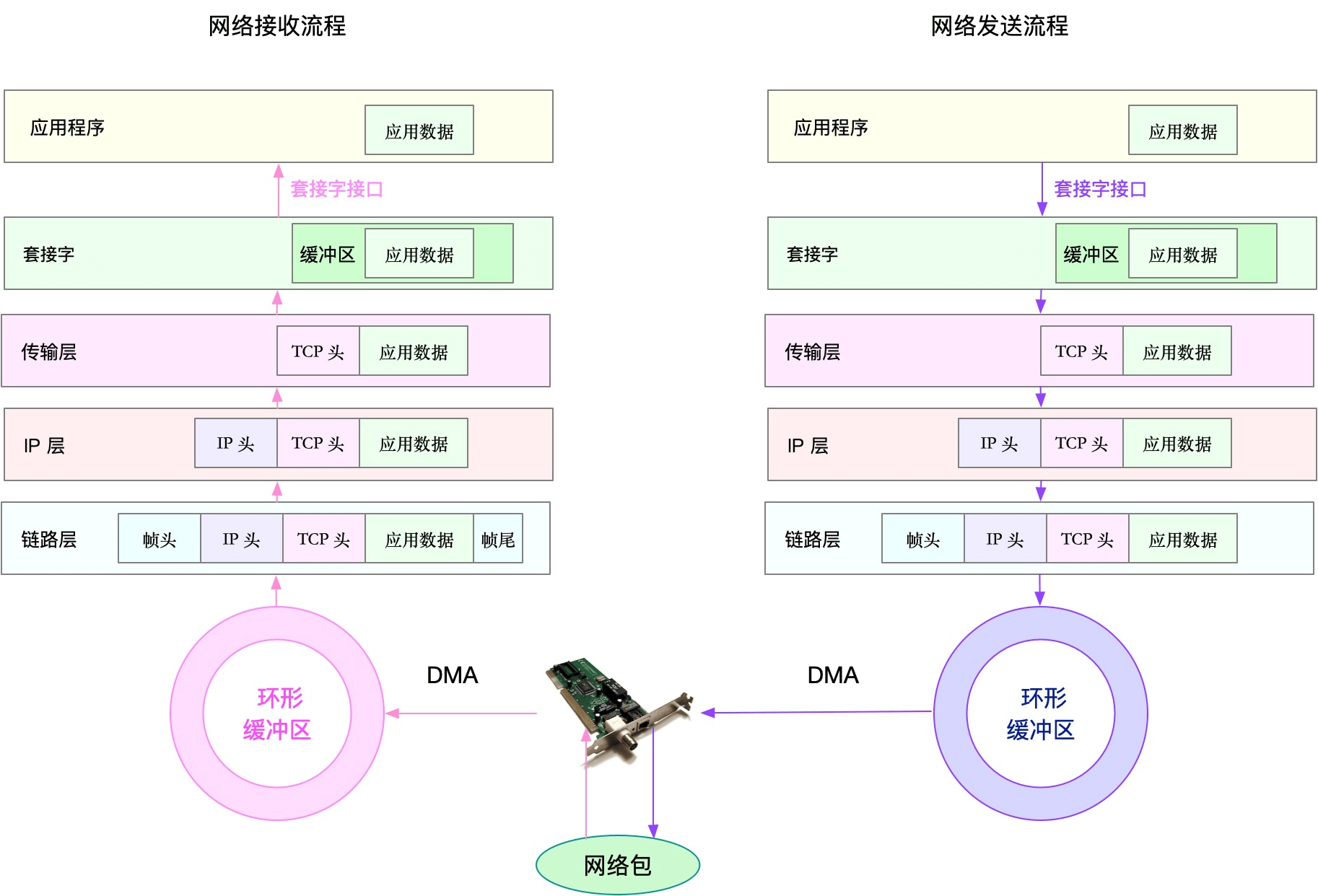
应用程序优化
从网络I/O的角度来说,主要有下面两种优化
第一种是最常用的I/O多路复用技术epoll,主要用来取代select和poll。这其实是解决C10K问题的关键,也是目前很多网络应用默认使用的机制
第二种是使用异步I/O(AIO)。AIO使用比较复杂,需小心使用
从进程工作模型上来说
第一种,主进程+多个worker子进程。其中,主进程负责管理网络连接,而子进程负责实际的业务处理。
第二种,监听到相同端口的多进程模型。这种模型下,所有进程都会监听相同接口,并开启SO_REUSEPORT选项,由内核负责,把请求负载均衡到这些监听进程中去。
除网络I/O和进程的工作模型外,应用层的网络协议优化,也是至关重要的,有常见几种优化方法:
- 使用长连接取代短链接,可以显著降低TCP建立连接的成本。在每秒请求次数较多时,这样做的效果非常明显。
- 使用内存等方式,来缓存不常变化的数据,可以降低网络I/O次数,同时加快应用程序的响应速度。
- 使用Protocol Buffer等序列化的方式,压缩网络I/O的数据量,可以提高应用程序的吞吐
- 使用DNS缓存、预取、HTTPDNS等方式,减少DNS解析的延迟,也可以提升网络I/O的整体速度
套接字
套接字可以屏蔽掉Linux内核中不同协议的差异,为应用程序提供统一的访问接口。每个套接字,都有一个读写缓冲区
- 读缓冲区,缓存了远端发过来的数据。如果读缓冲区满,就不能再接收新的数据。
- 写缓冲区,缓存了要发出去的数据。如果写缓冲区已满,应用程序的写操作就会被阻塞
所以为了提高网络吞吐量,你通常需要调整这些缓冲区的大小,比如:
- 增大每个套接字所允许的最大缓冲区大小net.core.optmem_max
- 增大套接字接收缓冲区大小(最大TCP数据接收窗口大小)net.core.rmem_max和发送缓冲区大小(最大TCP数据发送窗口)net.core.wmem_max
- 增大TCP接收缓冲区大小net.ipv4.tcp_rmem和发送缓冲区的大小net.ipv4.tcp_wmem
net.ipv4.tcp_rmem 为自动调优定义socket使用的内存
- 第一个值是socket接收缓冲区分配的最小字节数
- 第二个值是默认值(会被rmem_default覆盖)
- 第三个值是接收缓冲区空间的最大字节数(该值会被rmem_max覆盖)
net.ipv4.tcp_wmem类似,不再赘述
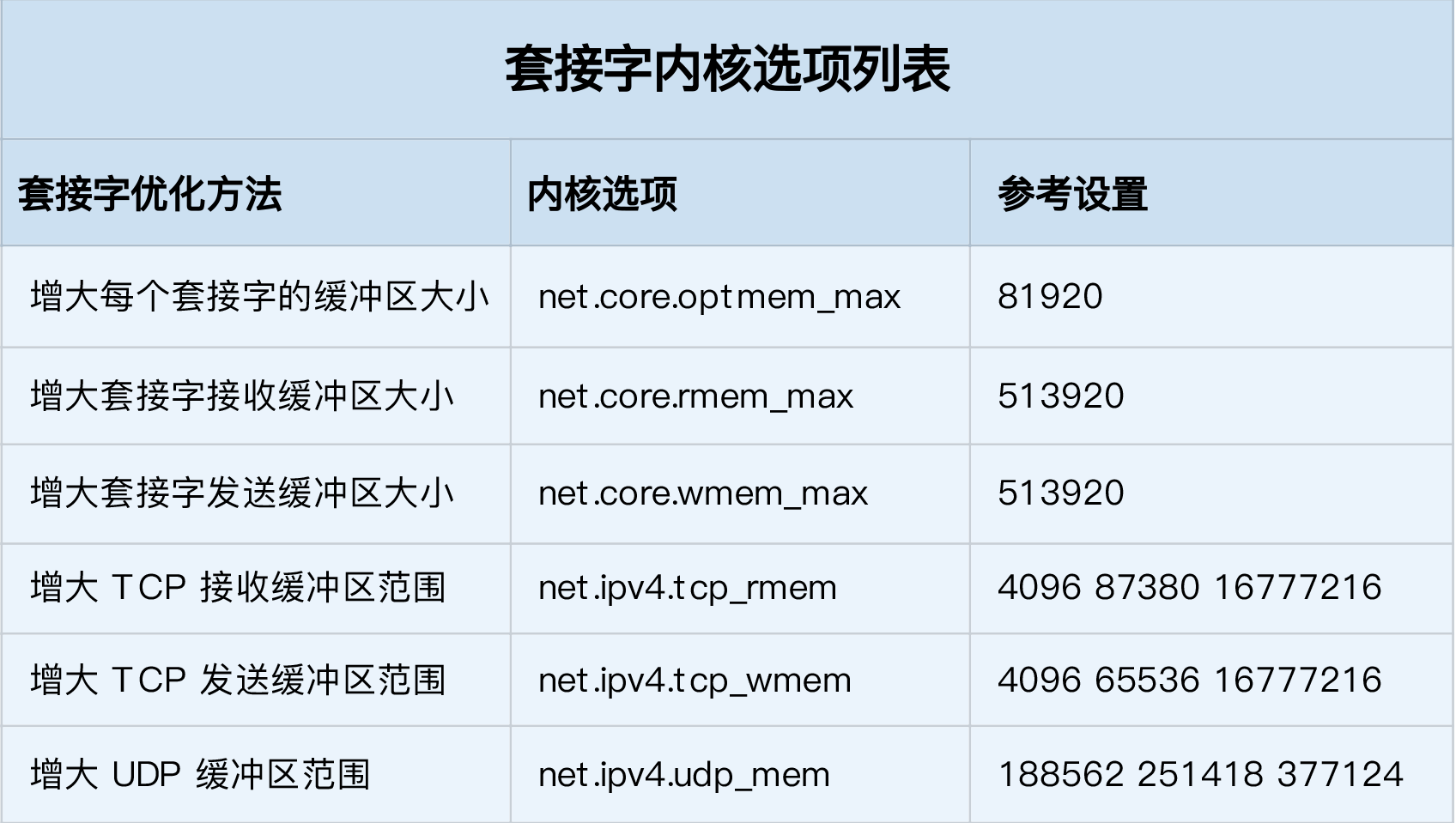
除此之外,套接字接口还提供了一些配置选项,用来修改网络连接的行为
- 为TCP连接设置TCP_NODELAY后,可以禁用Nagle算法
- 为TCP连接开启TCP_CORK后,可以让小包聚合成大包后再发送(注意会阻塞小包的发送)
- 使用SO_SNDBUF和SO_RCVBUF,可以分别调整套接字发送缓冲区和接收缓冲区的大小
传输层
传输层最重要的是TCP和UDP,这里的优化主要是对这两种协议的优化
首先来看TCP。要优化TCP,我们首先要掌握TCP协议的基本原理,比如流量控制、慢启动、拥塞避免、延迟确认以及状态流图(如下)等

掌握这些原理后,你就可以在不破坏TCP正常工作的基础上,对它进行优化。
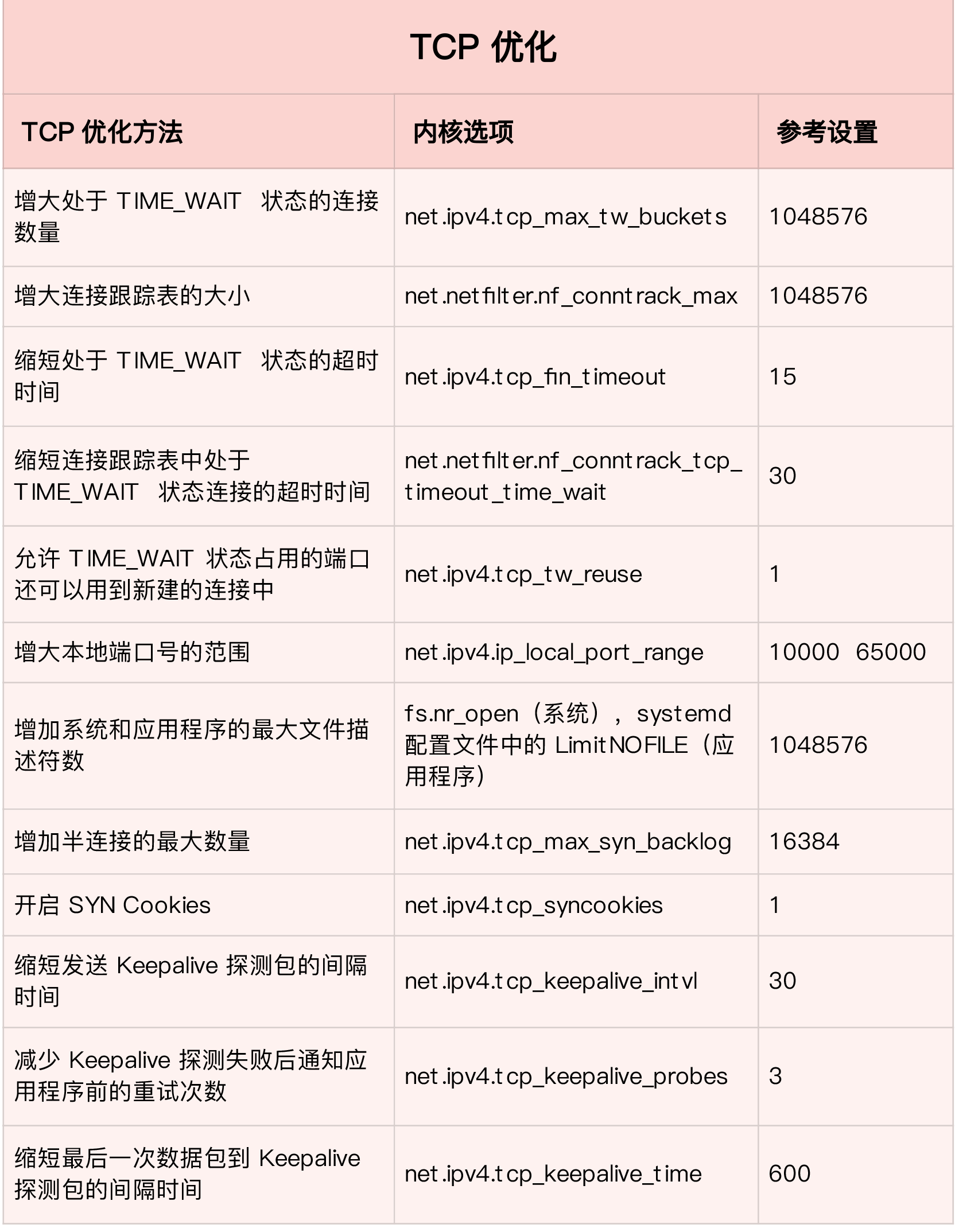
第一类,在请求数比较大的场景下,你可能会看到大量处于TIME_WAIT状态的连接,他们会占用大量内存和资源端口。这时通常有以下几种优化手段
- 增大处于TIME_WAIT状态的连接数量net.ipv4.tcp_max_tw_buckets,并增大连接跟踪表大小net.netfilter.nf_conntrack_max
- 减小net.ipv4.tcp_fin_timeout和net.netfilter.nf_conntrack_tcp_timeout_time_wait,让系统尽快释放它们所占用的资源。
- 开启端口复用net.ipv4.tcp_tw_reuse。这样,被TIME_WAIT状态占用的端口,还能用到新建的连接中。
- 增大本地端口范围net.ipv4.ip_local_port_range。这样就可以支持更多连接,提高整体的并发能力。
- 增加最大文件描述符的数量。你可以使用fs.nr_open和fs.file-max,分别增大进程和系统的最大文件描述符数;或在应用程序的systemd配置文件中,配置LimitNOFILE,设置应用程序的最大文件描述符
第二类,为了缓解SYN FLOOD等,利用TCP协议特点进行攻击而引发的性能问题。你可以考虑优化与SYN状态相关的内核选项,比如以下几点
- 增大TCP半连接的最大数量net.ipv4.tcp_max_syn_backlog,或者开启TCP SYN Cookies net.ipv4.tcp_syncookies,来绕开半连接数量限制的问题(注意这两个选项不可同时使用)
- 减少SYN_RECV状态的连接重传SYN+ACK包的次数net.ipv4.tcp_synack_retries
第三类,在长连接的场景中,通常使用keepalive来检测TCP连接的状态,以便对端连接断开后,可以自动回收。但是,系统默认的Keepalive探测间隔和重试册数,一般都无法满足应用程序的性能要求。这时你需要优化keepalive相关的内核选项,比如:
- 缩短最后一次数据包到keepalive探测宝的检测时间ne.ipv4.tcp_keepalive_time;
- 缩短发送keepalive探测包的间隔时间net.ipv4.tcp_keepalive_intvl
- 减少keepalive探测失败后,一直到通知应用程序前的重试次数net.ipv4.tcp_keepalive_probes
说完TCP,再看UDP的优化
- 跟上篇套接字部分一样,增大套接字缓冲区大小以及UDP缓冲区范围
- 跟前面TCP部分提到一样,增大本地端口号的范围
- 根据MTU大小,调整UDP数据包的大小,减少或避免分片的发生
网络层
网络层,负责网络包的封装、寻址和路由,包括IP、ICMP等常见协议。在网络层,最主要的优化,其实就是对路由、IP分片以及ICMP等进行调优
第一种,从路由和转发的角度出发,你可以调整下面内核选项
- 在需要转发的服务器中,比如作为NAT网关的服务器或者使用Docker容器时,开启IP转发,即设置net.ipv4.ip_forward=1
- 调整数据包的生存周期TTL,比如设置net.ipv4.ip_default_ttl=64,注意增大该值会降低系统性能
- 开启数据包的反向地址校验,比如设置net.ipv4.conf.eth0.rp_filter=1。这样可以防止IP欺骗,并减少伪造IP带来的DDoS问题
第二种,从分片的角度出发,最主要的是调整MTU的大小
通常,MTU的大小应该根据以太网的标准来设置。以太网标准规定,一个网络帧最大为1518B,那么去掉以太网头部的18B后,剩余的1500就是以外网MTU的大小。
另外,现在很多网络设备都支持巨帧,如果是这种环境,你还可以把MTU调大到9000,以提高网络吞吐量
第三种,从ICMP的角度出发,为了避免ICMP主机探测、ICMP FLood等问题,你可以通过内核选项来限制ICMP的行为
- 比如,你可以禁用ICMP协议 net.ipv4.icmp_echo_ignore_all = 1。这样外部主机就无法通过ICMP来探测主机
- 或者你还可以进制广告ICMP net.ipv4.icmp_echo_ignore_broadcasts=1
链路层
链路层负责网络层在物理网络中的传输,比如MAC寻址、错误侦测以及通过网卡传输网络帧等。
由于网卡收包后调用的中断处理程序(特别是软终端),需要消耗大量的CPU。所以将这些中断处理程序调度到不同的CPU上来执行,就可以显著提高网络吞吐量。通常可采用下面方法
- 可以为网卡硬终端配置CPU亲和性(smp_affinity),或者开启irqbalance服务
- 再者,你可以开启RPS(Receive Packet Steering) 和RFS(Receive Flow Steering),将应用程序和软中断的处理,调度到相同的CPU上,这样就可以增加CPU缓存命中率,减少网络延迟
我们整理一下网络优化思路:
- 在应用程序中,主要优化I/O模型、工作模型以及应用层的网络协议
- 套接字层中,主要优化套接字的缓冲区大小
- 在传输层主要优化TCP和UDP协议
- 在网络层中,主要优化路由、转发、分片以及ICMP协议
- 最后在链路层中,主要优化网络包的收发、网络功能卸载以及网卡选项
工作管理
工作管理的意义
工作管理的意义在于将多个工作囊括在一个终端,并取其中的一个工作作为前台,来直接接收该终端的输入输出以及终端信号。 其他工作在后台运行。
相关命令
Jobs命令用于在管理当前shell下的任务
|
|
计划任务
|
|
Ftp
|
|
工具
发行版
ubuntu
dpkg
dpkg是Debian package的缩写,是“Debian”操作系统专用的套件管理系统,用户软件的安装、更新、卸载。所有源自“Debian”的Linux发行版都使用dpkg,例如”utuntu”
dpkg不解决依赖问题,所以安装软件包建议使用apt或aptitude
deb是Debian软件包的扩展名,类似rpm包
|
|
apt
apt(Advanced Packaging Tool)是linux上的一款安装包管理工具,用于解决deb包的依赖问题,apt是建立在dpkg之上的软件包管理工具
|
|
aptitude
aptitude是一款基于apt建立的软件包管理工具
|
|
centos
|
|
rpm
|
|
FAQ
1.如何添加启动项
答: /etc/rc.local
2.webhook使用中碰到一个问题,本地项目提交push请求后,通过webhook 将向设定好的url发送一个post请求,该url接收到请求后内部使用php的shell_exec进行对服务器上的某目录进行git pull操作
结果出现以下问题
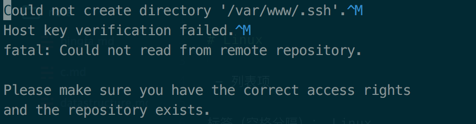
i.接收不到post过来的数据
ii.shell_exec执行git pull时提示无法创建目录/var/www/.ssh
第一个问题
该问题其实是由于获取请求数据时使用`$_POST`导致。
`$_POST`变量只能接收Content-Type是application/x-www-form-urlencoded 或 multipart/form-data 的内容
解决方法就是改用file_get_contents('php://input')
php://input是个可以访问请求原始数据的只读流,POST请求下,建议使用'php://input'来获取数据
第二个问题
其实根据提示,该问题转化为了web服务器执行用户对远端主机免密登录的问题
第一步:在/etc/nginx/nginx.conf中看到nginx默认执行用户是www-data
第二步:然后查找www-data的用户目录,查看后发现是/var/www
cat /etc/passwd|grep www-data
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
第三步:对www-data用户目录授权,且生成公钥
chown -R www.www /var/www
sudo -u www-data ssh-keygen -t rsa
3.在windows上保存的文件默认会在结尾出现^M
答: 使用unix2dos修正 unixdoc filename
4.为什么关闭会话后,正在执行的命令也会被关闭
用户会话关闭时,会将当前会话相关的进程全部关闭
5.为什么用php的exec方法执行的命令 在页面关闭后还会继续执行
因为命令是使用web服务器的启动用户来进行的,并不涉及会话关闭,所以进程依旧存在,命令依旧执行
6.如何查询Linux文档
Linux系统中man被分为多个卷
|
|
例如要查询系统调用mount, 需要使用man 2 mount 或man 3 mount
7.常见linux 命令安装
经常见到进入到docker中执行xxx命令 结果返回command not found ,以下是一些常见命令安装
|
|
8.安装软件时,找不到对应的包,如何解决
比如在ubuntu下安装perf时,apt-get update&&apt-get install linux-perf-4.9(注意perf与kernel版本有关) 却返回无对应包,这表示当前机器源内不存在这个软件包,需要额外添加包含该软件包的源
最后在网上搜到这个https://packages.debian.org/stretch/linux-perf-4.9
然后在/etc/apt/sources.list中加上deb http://ftp.cn.debian.org/debian stretch main,然后apt-get update更新数据包,又爆出如下问题
|
|
缺少公钥,我们可以通过以下方式导入
|
|
9.快速查找hisitory命令
ctrl+r 如果需要继续反向查找,继续按ctrl+r
等同于history|grep xxxx
10.ulimit
ulimit全称user limit,是一个shell builtin命令,用于获取或设定用户系统资源限制。
|
|
11.Linux软件包安装方式
Linux安装包分为二进制形式和源码形式
二进制形式安装包是指事先已经编译好的二进制形式的软件包,优点是安装方便,缺点是灵活性较差。
常见的有rpm、tar.gz形式的二进制安装包
源代码形式安装包是指该软件需要用户自己编译成可执行的二进制文件并安装,优点是配置灵活,适应多种操作系统级编译环境,缺点是难度较大
12.shell关闭缓冲区
shell中有时在使用管道时由于缓冲区的原因,无法及时看到输出,通过使用stdbuf命令操作关闭缓冲区可以解决问题。
|
|
13.DMA
计算机硬件上使用DMA来访问磁盘/网络等IO,请求发出后,CPU就不再管了,直到DMA完成任务,最后通过中断告诉CPU IO操作完成。所以,单独一个IO时间内,对CPU的占用是很少的,线程阻塞后就不会再占用CPU,CPU时间交给其他线程了。
虽然IO不会占用大量CPU时间,但是频繁的IO还是会影响CPU产生很大影响,比如上下文切换带来的额外开销等。
CPU计算文件地址=>委派DMA读取文件=>DMA接管总线=>CPU的A进程阻塞,挂起 CPU切换到B进程=>DMA读完文件后通知CPU(一个中断异常=>CPU切换回A进程操作文件
另外一点,阻塞只是线程阻塞,不会对cpu造成影响