简介
http协议是以ACSII码传输,建立在TCP/IP之上的应用层规范,默认端口为80
协议有如下特点:
无连接: 限制每次连接只处理一个请求,服务器处理完客户请求,并收到客户的应答后,即断开连接,采用这种方式可以节省传输时间无状态: HTTP协议本身不会对发送过的请求和相应的通信状态进行持久化处理。这样做的目的是为了保持HTTP协议的简单性,从而能够快速处理大量的事务,提高效率。
请求方法有: GET/PUT/POST/DELETE等
请求及响应
请求
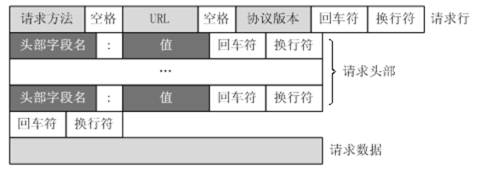
|
|
响应
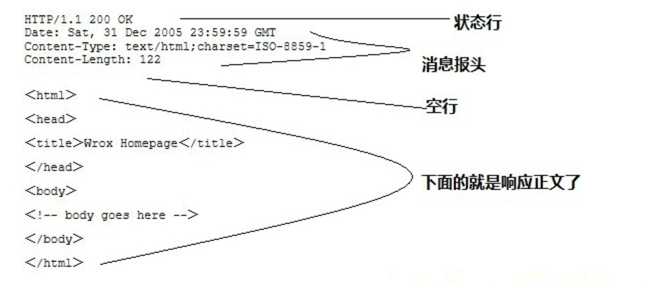
|
|
常见响应头
Cache-Control
Cache-Control指定请求和响应的缓存机制
常见取值有:
no-cache: 数据内容不能被缓存, 每次请求都重新访问服务器, 若有max-age, 则缓存期间不访问服务器.
no-store: 不仅不能缓存, 连暂存也不可以(即: 临时文件夹中不能暂存该资源)
private(默认): 只能在浏览器中缓存, 只有在第一次请求的时候才访问服务器, 若有max-age, 则缓存期间不访问服务器.
public: 可以被任何缓存区缓存, 如: 浏览器、服务器、代理服务器等
max-age: 相对过期时间, 即以秒为单位的缓存时间.
no-cache, private: 打开新窗口时候重新访问服务器, 若设置max-age, 则缓存期间不访问服务器.
private, 正数的max-age: 后退时候不会访问服务器
no-cache, 正数的max-age: 后退时会访问服务器
|
|
状态码
|
|
Nginx access日志
|
|
连接管理
- 短链接(1.0默认模型)
- 长连接(1.1默认模型)
一个长连接会保持一段时间,重复用于发送一系列请求,节省新建TCP连接握手的时间。
这个连接在空闲一段时间后会被关闭(服务器可以使用Keep-Alive协议头来指定一个最小的连接保持时间)更多解释见
持久连接章节 - http流水线
在http2中流水线模型被更好的算法替代
持久连接
随着时间推移,网页变得越来越复杂,每个页面可能要发起很多请求,如果每次都简历一个tcp连接就显得很低效,于是keep-alive被提出解决这个问题
我们知道HTTP协议采用”请求-应答”模式,当使用普通模式,即非keep-alive模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接(HTTP协议为无连接协议);当使用keep-alive模式(持久连接)时,keep-alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,keep-alive功能避免了建立或重新建立连接。
如果客户端浏览器支持keep-alive,那么就在http请求头中添加一个字段connection:keep-alive,当服务器收到附带有connection:keep-alive的请求时,它也会在响应头中添加一个同样的字段来使用keep-alive。这样一来,客户端和服务器之间的http连接就会被保持,不会断开(超过keep-alive规定的时间,意外断电等情况除外),当客户端发送另外一个请求时,就使用这条已经建立的连接。
http1.1版本中,默认所有连接都会被保持,如果加入connection:close才关闭。目前大部分浏览器都使用http1.1协议,所以是否能完成一个完整的keep-alive就看服务器设置情况。
keep-alive简单就是保持当前的TCP连接,避免了重新建立连接。
HTTP长连接不可能一直保持,例如keep-alive:timeout=5,max=100,表示这个TCP通道可以持续5秒,max=100,表示这个长连接最多接受100次就断开。
HTTP是一个无状态协议,这意味着每个请求都是独立的。另外keep-alive也不能保证客户端和服务器之间的连接一定是活跃的,在HTTP1.1版本中也是如此。唯一能保证的是当连接被关闭时你能得到一个通知,所以不应该让程序依赖于keep-alive的持续保持连接性,否则会有意想不到的后果