什么是redis
Redis是key-value型的内存数据库
Redis是单线程的
默认端口为6379
启动
redis-server /usr/local/redis/etc/redis.conf
如果需要后台运行,修改redis.conf中的daemonize为yes
配置
|
|
数据类型
key命令
|
|
String
set/get
|
|
示例: 锁的简单实现
|
|
incr/decr
这是一个针对字符串的操作,因为 Redis 没有专用的整数类型,所以 key 内储存的字符串被解释为十进制 64 位有符号整数来执行 INCR 操作。
|
|
示例: 计数器
|
|
示例: 限速器
限速器用于限制一个操作可以被执行的速率
bitmap
|
|
incr decr incrby decrby只有当值为整数时可以使用
value加不加引号都作为字符串处理
List
- list类型使用双向链表实现,不支持查找且不排重
- 常用场景
消息队列 - 基本命令
|
|
Set
- 哈希表实现,支持查找且排重
- 常用场景
用于记录做过某些事情,如投票系统以日期为key,将已投用户的id存入。可以简单查询用户当前是否投票 - 常用命令
|
|
Set没有阻塞式随机弹出bspop,不过我们可以借助辅助list实现类似功能
|
|
Sorted Set
- 使用哈希表和跳跃表(skiplist)实现。跟无序集合相比,添加了score成员记录顺序,集合元素依旧唯一
- 常用场景
set可以做的zset都能实现,且还可完成更多需求,例如使用zset构建一个具有优先级的队列,又或实现排行榜应用按顶帖数排序,排序的值设定为score,具体帖子内容设置为相应的value,每次用户顶帖时,指定zincrby 去更新key的score即可 - 常用命令
|
|
Hash
- 哈希类型每个Key对应一个哈希表,哈希表中使用field=value这种键值对存储。
- 常用场景
存储对象,如存储用户信息 - 常用命令
|
|
列表list与有序集合
列表内部使用双向链表实现,所以访问两端数据速度快,访问中间内容速度慢,更适用于新鲜事、日志这样这样很少访问中间元素的应用
有序集合使用散列表和跳跃表实现,读取任何位置的数据都很快(O(log(N))
列表中不能自由调整某元素的位置,但有序集合可以通过调整分数实现
有序集合比列表耗费更多内存
有序集合数据自动排重,列表数据可以重复
排序
redis支持对list、set、sorted set排序
sort key [by pattern] [limit start count] [asc|desc] [alptha] [store dstkey]
|
|
练习
服务器
|
|
处理过期数据
Redis通过两个步骤进行过期处理
步骤1: 每0.1秒主动监测并删除部分过期数据
步骤2: 每次访问数据时,判断数据是否已经过期
内存淘汰
当内存不足时启用内存淘汰策略,redis有3种策略,通过maxmemory-policy设定
1.随机淘汰算法: 随机删除一个key
2.LRU淘汰算法: 删除一个最近最少访问的key
3.TTL淘汰算法: 删除一个最快过期的key
[内存淘汰](http://ifeve.com/redis-lru/)
持久化
快照(snapshot)
RDB是redis默认的持久化策略。
RDB是一个经过压缩的二进制文件,采用RDB持久化时服务器只会保存一个RDB文件。
内部实际上是一个定时器事件,每隔固定时间去检查当前数据改变的次数与时间是否满足配置的持久化触发条件,如果满足则自动执行bgsave保存数据
在执行bgsave期间,客户端发送的save、bgsave会被服务器拒绝(防止产生竞争)
|
|
日志追加(AOF)
默认redis异步地通过快照方式向磁盘持久化数据。当redis进程出现问题或者机器断电发生时,会导致丢失一段时间的数据(取决于snapshot配置)。
AOF是另一种可选的更可靠的持久化策略。出现上述问题时,redis只会丢失一秒或一个写操作的数据(取决于aof配置)。
|
|
AOF方式通过write函数把写语句(写或修改)追加到文件尾部(默认是appendonly.aof)。
redis重启时会读取appendonly.aof文件中所有命令并依次执行,从而将数据写入到内存中。
AOF重写
appendonly.aof文件随着命令执行次数增加而不断膨胀,而其中有很多相同效果的语句,如调用set name xk 100次,那么appendonly.aof中就有100条。
这个问题,可以通过使用bgrewriteaof命令重写AOF日志解决
AOF重写缓冲区
redis是单线程的,为了在重写时不阻塞服务,redis使用子进程方式进行AOF重写-bgrewriteaof
所谓的“重写”其实是一个有歧义的词语, 实际上, AOF 重写并不需要对原有的 AOF 文件进行任何写入和读取, 它针对的是数据库中键的当前值。
但是这里产生了另外一个问题: 子进程在AOF重写时,父进程还在继续处理请求,这些请求有可能对数据库进行修改,这导致服务器当前状态和重写后的AOF文件所保存的服务器不一致。为此redis引入了AOF重写缓冲区。
AOF重写期间的命令会同时写到当前AOF文件及AOF重写缓冲区,当AOF重写完成后,会向父进程发送一个信号,父进程收到信号后会阻塞当前服务,将AOF重写缓冲区中的写命令写入到重写的AOF文件中(保证了AOF文件数据库和当前数据库一致),之后使用重写的AOF文件覆盖原有AOF文件。
持久化策略选择
默认redis使用snapshot方式持久化数据。
当服务器载入RDB时,REDIS一直处于阻塞状态,直到载入完毕。
可以同时开启snapshot和aof策略,服务器启动时会优先加载AOF文件,没有则去加载RDB文件。
如果服务器初始使用rdb方式,之后开启aof,这时重启redis会根据aof进行载入,原来rdb中的数据无法加载到数据库中。
集群
主从
redis实现主从很简单,在slave服务器上配置
slaveof 192.168.1.1 6379 #指定master的IP和端口
* 搭建主从后,从服务器系统不允许写操作
* 可使用info命令查看主从是否配置成功
* master配置了密码,slave同样需要指明master密码 masterauth password
主从同步流程
1.从服务器连接主服务器,发送sync命令
2.主服务器执行bgsave,并使用缓冲区记录bgsave之后执行的所有写命令
3.主服务器bgsave执行完毕,向从服务器发送快照文件,从服务器丢弃所有旧数据,开始载入快照文件
4.主服务器快照发送完毕,开始向从服务器发送缓冲区里的写命令
redis-cluster
访问控制
#设置登录密码(/etc/redis.conf中)
requirepass xxxx
#使用密码登陆
redis-cli -h 127.0.0.1 -p 6379 -a password
或
redis-cli登录后使用auth xxx认证
发布/订阅
说明
适用于消息分发,不推荐作为队列使用
作用
解耦系统,如系统AB使用不同语言
命令
subscribe channel1 channel2
unsubscribe channel1 channel2
psubscribe news.* tweet.*
punsubscribe news.* tweet.*
publish channel1 msg
php实现
|
|
事务
背景
有客户端AB A中有一系列操作需要顺序完成,且中间不允许其他客户端对数据修改,这时候就用到了事务
解析
事务将多个有序命令打包成原子操作,服务器在执行那碗事务的所有命令后,才会处理其他客户端的其他命令
事务中某条/某些命令执行失败了,事务队列中的其他命令仍然会继续执行
redis事务只原子性的,没有回滚机制
|
|
应用场景
数据缓存
手机验证码
定期更新的内容
访问频率限制
思路:
方法1
使用string实现
FUNCTION LIMIT_API_CALL(ip)
ts = CURRENT_UNIX_TIME()
keyname = ip+":"+ts
current = GET(keyname)
IF current != NULL AND current > 10 THEN
ERROR "too many requests per second"
END
IF current == NULL THEN
MULTI
INCR(keyname, 1)
EXPIRE(keyname, 1)
EXEC
ELSE
INCR(keyname, 1)
END
PERFORM_API_CALL()
方法2
使用List实现
FUNCTION LIMIT_API_CALL(ip)
current = LLEN(ip)
IF current > 10 THEN
ERROR "too many requests per second"
ELSE
IF EXISTS(ip) == FALSE
MULTI
RPUSH(ip,ip)
EXPIRE(ip,1)
EXEC
ELSE
RPUSHX(ip,ip)
END
PERFORM_API_CALL()
END
参考
http://redisdoc.com/string/incr.html
取最新N条文章
使用lpush lastest.posts id将文章id插入到列表中
使用ltrim lastest.posts 0 5000,使列表永远保存最新的5000条数据
使用lrange lastest.posts 0 num 获取最新num条数据
取TOP N/排行榜
score表示热度
zadd postlist 0 1
zincrby postlist 1 1
zincrby postlist 1 1
zincrby postlist 1 1
zadd postlist 1 2
zadd postlist 2 3
zrevrange postlist 0 N 查出top N
计数器
如商品喜欢数、评论数、浏览数,用户关注数、粉丝数、未读消息数等
hset product:1 like 1
hincrby product:1 like 1 喜欢书+1
存储社交关系
譬如将用户的好友/粉丝/关注,可以存一个sorted set中,score可以是timestamp,这样求两个人的共同好友的操作,只需要用求交集的命令即可
zadd user:1:follow 1456999063 3
zadd user:1:follow 1456999063 4
zadd user:1:follow 1456999063 5
zadd user:2:follow 1456999063 4
zadd user:2:follow 1456999063 5
zinterstore out:1:2 user:1:follow user:2:follow
zrange out:1:2 0 -1
队列
模式
生产者消费者模式
多个消费者监听队列,谁先抢到消息谁就会从队列中取走消息,即每个消息最多被1个消费者接收
发布者订阅者模式
多个消费者监听队列且会收到相同的一份消息,即每个消息可以被多个消费者接收
消息分发与消息队列
可以为每个接收方设置一个信箱(list or set),发送消息就是把消息加到接收方的信箱,接受消息就是获取自己信箱中的内容,分发的方式采用PUB/SUB,队列实现使用brpop()
生产者消费者模式使用
使用list构建普通队列
rpush入列,lpop出列
使用sorted set实现优先级队列
生产者消费者模式
zadd mysset 1 'one'
zadd mysset 1 'two'
zadd mysset 2 'three'
假定score越高优先级越高,使用zrevrange mysset 0 0取出score最大的一条的值为value
使用zrem mysset value消费value
发布者订阅者模式使用
使用pub/sub模式
* 队列不建议使用该方式实现
|
|
用作缓存替代memcacahe
存储session
方式1
使用phpredis扩展,直接修改session配置
session.save_handler = redis
session.save_path = "tcp://host1:6379?weight=1, tcp://host2:6379?weight=2&timeout=2.5, tcp://host3:6379?weight=2"
redis中的内容 PHPREDIS_SESSION:kv8nkmshk0v3umi2f9s2v4nn91
方式2
使用session_set_save_handler修改session处理机制
session_set_save_handler(callback open,callback close,callback read,callback write,callback destroy,callback gc);
我们需要处理其中的read,write,destroy这三个函数
|
|
参考
FAQ
1.数据结构设计
blog的关系型表
post
content
author
date
author
name
comment
name
email
date
解析: redis中的key很占空间,不建议以post:[post_id]:author这样来建立key
建议使用字段名作为key,id作为字段
HASH post:author
1 32
2 58
HASH post:name
1 sxk
2 lxp
HASH post:date
1 20324123412
2 20324123412
HASH post:comments
1 2,3,4 (序列化)
2 3,4,5
.....
参考资料:
https://www.v2ex.com/t/15712
2.redis是单线程程序,为什么这么快?
1.纯内存操作
2.因为是单线程,无需考虑上下文切换和竞争
3.使用epoll实现多路复用IO,不在io上浪费时间
练习
数据类型练习
---------string-------------
set name sxk
setnx name sxk
get name sxk
getset name sxk2
mset age 1 sex 1
mget age sex
incr age
decr age
incrby age 2
decrby age 2
---------list--------------
lpush mylist one
rpop mylist one
lpush mylist one
lpush mylist two
lpush mylist three
llen mylist
lrange mylist 0 3
---------set--------------
sadd myset one
sadd myset two
sadd myset three
smembers myset
srem myset two
sismember myset one
spop mysset
srandmember myset
smove myset2 myset1 four
sinter myset1 myset2
---------sorted set-------
zadd mysset 1 one
zadd mysset 2 two
zadd mysset 3 three
zadd mysset 4 four
zscore mysset one
zrem mysset four
zcard mysset
zrange 0 3
zcount mysset 2 3
zincrby mysset 2 two
zrank mysset one
#获取0<score<=3的key和值
zrangebyscore mysset (0 3 withscores
#获取 负无穷<score<正无穷的key和值
zrangebyscore mysset -inf +inf withscores
#以score从小到大的顺序获取mysset的全部value
zrange mysset 0 -1 withscores
---------hash-----------
hsetnx user name sxk
hsetnx user age 18
hsetnx user sex 1
hgetnx user name
hexists user name
hlen user
hdel user name
hkeys user
hvals user
FAQ
1.redis中incr自加有没有上限?
答: incr操作最大值值限制在64位有符号数字表示之内,超过后incr报错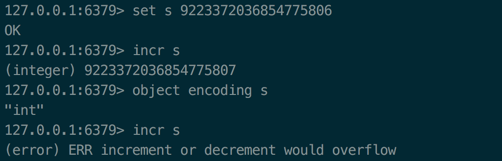
没超过64位之前值编码为int,超过后值编码为ember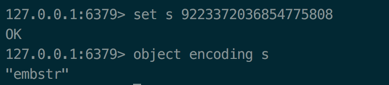
2.